AI agents that research before coding mark a shift from hallucination-prone code generation to more reliable outputs. Instead of spitting out buggy scripts from thin air, these systems scour documentation, Stack Overflow, and papers first. A recent Hacker News thread highlights “Research-Driven Agents,” where prototypes solve real-world coding tasks 2-3x better than baselines. This matters because current LLMs fail 80-90% on software engineering benchmarks without context—retrieval fixes that.
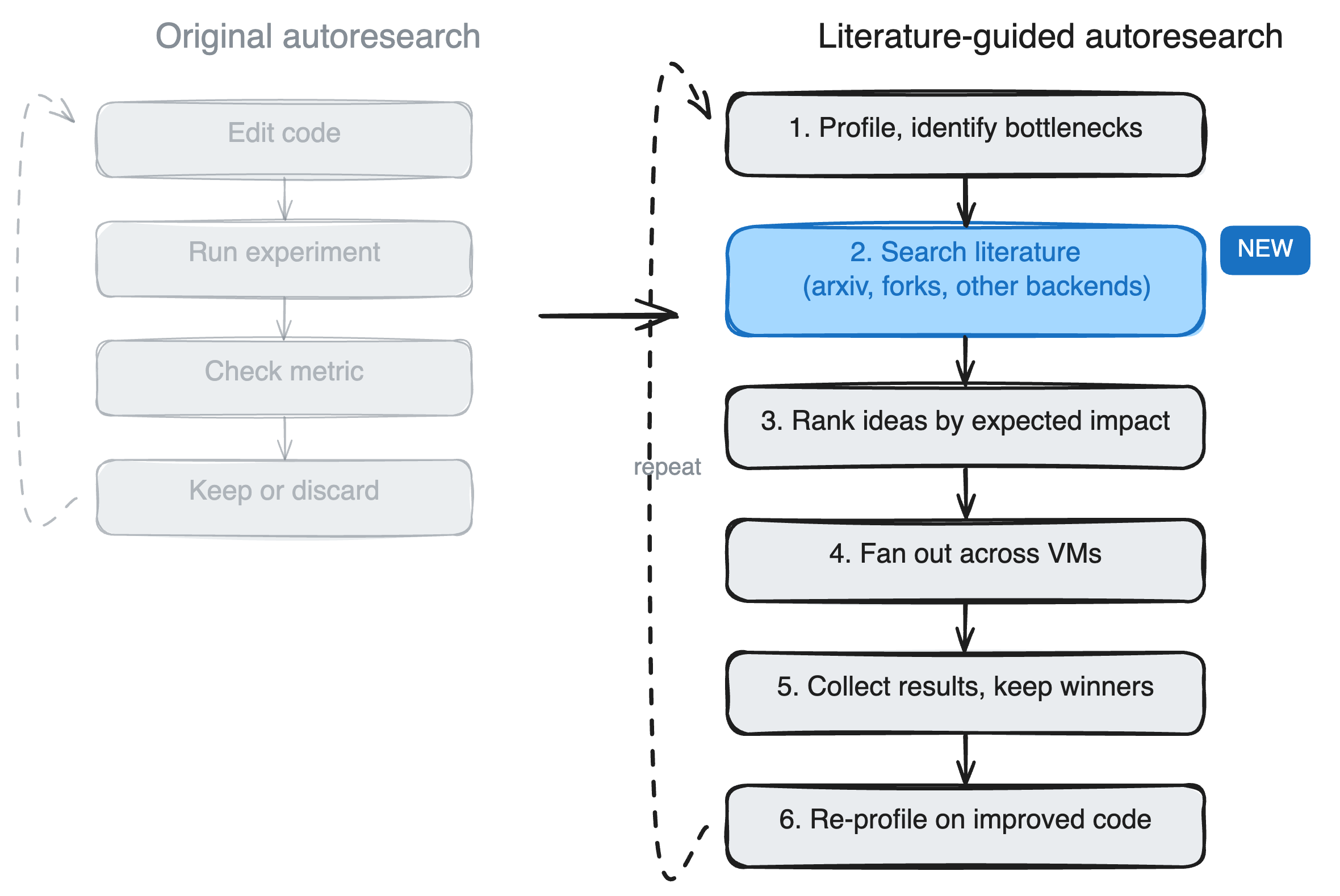
How Research-Driven Agents Work
These agents follow a simple loop: analyze the task, search for relevant info, read and synthesize it, then code. Take the prototype from the HN discussion—it uses tools like web search and doc retrieval to fetch specifics before acting. For instance, coding a Redis cache handler? It pulls the official Redis docs, recent GitHub issues, and Python client examples first.
Under the hood, it’s retrieval-augmented generation (RAG) on steroids. Embeddings index vast codebases or web scrapes. A query like “implement JWT auth in FastAPI” retrieves top matches, which the LLM summarizes into a plan. Then it codes with citations. Tools like LangChain or LlamaIndex handle the plumbing, but custom agents add reasoning steps: verify facts, cross-reference sources, iterate if wrong.
Numbers back it up. On SWE-bench, a dataset of 2,294 real GitHub issues, vanilla GPT-4o solves 14%. Agentic setups with search hit 25-30%. The research-driven variant in the thread claims 33% on subsets, edging out competitors like Devin AI (claimed 13.8% verified). HumanEval, simpler function completion, jumps from 85% to 95% pass@1 with docs injected.
Benchmarks and Real-World Limits
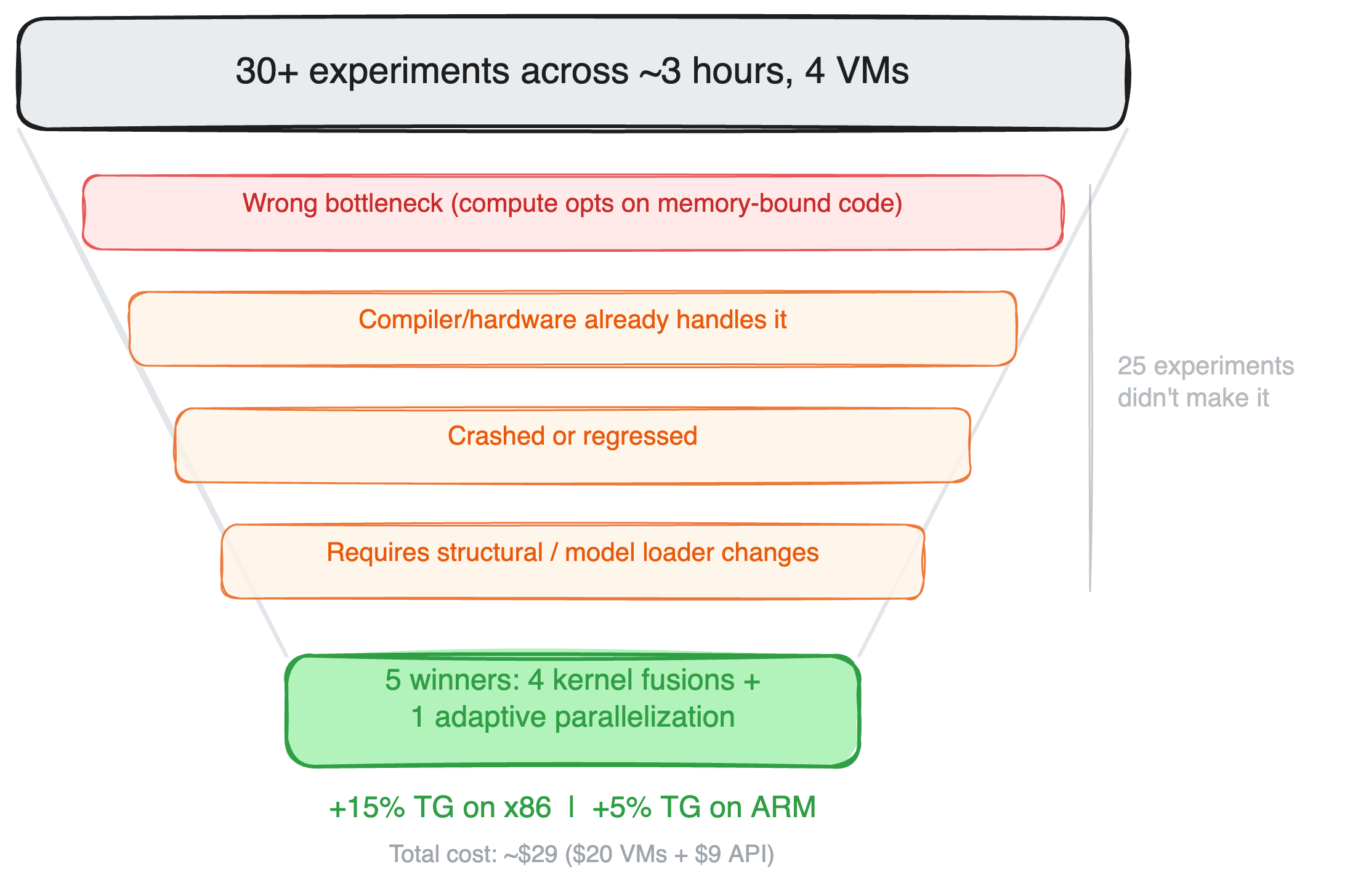
SWE-bench exposes the gap: tasks demand repo navigation, dependency wrangling, tests. Base agents flail without context. Research steps shine here—agents that “read before coding” parse READMEs, hunt bugs in issues. One experiment: on LeetCode hard problems, retrieval boosts solve rate from 40% to 65%.
But skepticism is warranted. Compute costs soar—each search adds 5-10x tokens, latency hits minutes per task. Hallucinations persist; agents cherry-pick bad sources or mis-summarize. Security risks too: pulling unvetted Stack Overflow snippets invites vulns. In the HN thread, users note failures on novel tasks without web analogs, like proprietary APIs.
Fair comparison: humans do this daily—Google before Stack Overflow before code. Agents mimic that, but LLMs’ reasoning is brittle. o1-preview style chain-of-thought helps, but retrieval grounds it. Open-source wins: projects like Aider (edits codebases via Git) or SWE-agent integrate search, free on GitHub. Run
$ pip install aider-chat
$ aider --model gpt-4o your_repo/to test— it auto-searches docs.
Why This Matters for Tech and Finance
Implications hit hard. Software eats the world; reliable auto-coding accelerates dev 10x. Finance firms churn trading algos, risk models—agents reading SEC filings or QuantLib docs first cut bugs that cost millions. Crypto? Smart contract audits via auto-research could prevent $4B+ yearly hacks (2023 DeFi losses).
Job shift: juniors freed for architecture, seniors audit agent outputs. But security pros worry—proliferating AI code means more subtle vulns. Firms like ours at Njalla see it: clients demand vetted tools. Expect enterprise forks: retrieval over private repos, not public web.
Bottom line: research-driven agents aren’t AGI coders yet, but they bridge LLM limits. Track SWE-bench leaderboards; 50% resolution unlocks $100B dev market. Skeptical take: hype cycles burn out, but this iterates on proven RAG. Devs, integrate now—your pull requests will thank you.