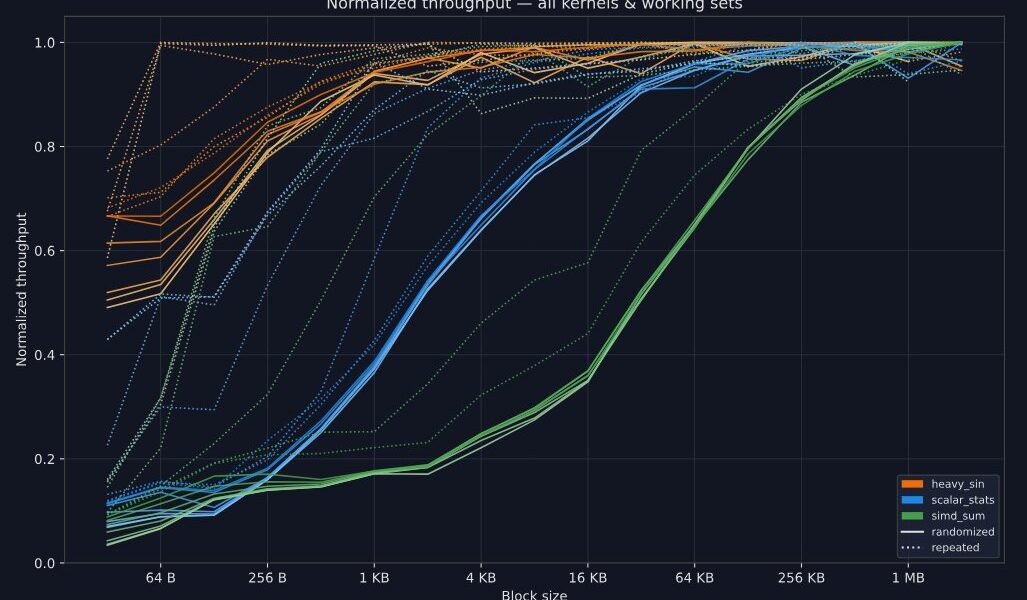
Modern CPUs demand linear memory access for peak performance, but block size matters less than you think. On a Ryzen 9 7950X3D, 1 MB blocks deliver full speed for most high-performance compute workloads. Drop to 128 KB blocks when your kernel chews through data at 1 cycle per byte or faster. Even 4 KB blocks work if processing takes 10+ cycles per byte. These sizes amortize the cost of jumping between blocks, letting you use chunked data structures without slowdowns.
This matters because real-world data rarely fits in one giant slab. Think machine learning batches, database pages, or parallel processing streams. Huge contiguous allocations waste memory and complicate scaling. Smaller blocks enable better locality, parallelism, and flexibility—without the perf hit everyone fears. The benchmark isolates this: process spans of spans (vector of linear blocks), measure throughput drop as blocks shrink.
Key Findings from the Benchmarks
The chart plots block size against cycles-per-byte for kernels from scalar stats (~0.75 cycles/byte) to heavier SIMD reductions. Peak performance kicks in at:
- 1 MB for compute-heavy workloads under 1 cycle/byte.
- 128 KB for ~1 cycle/byte.
- 4 KB above 10 cycles/byte.
Tested on Ryzen 9 7950X3D (Zen 4, 144 MB L3 cache via 3D V-Cache). Single-threaded kernels, total dataset 32 GB to stress DRAM. Results generalize to similar x86 CPUs with aggressive prefetchers and large LLCs. Skeptical note: AMD’s V-Cache inflates L3 hit rates; Intel Alder Lake/Raptor Lake might need larger blocks without it.
Setup: Isolating Block Jump Costs
Benchmarks allocate N blocks of size B, total 32 GB. Kernel takes std::span
Example: scalar_stats kernel aggregates mean, variance, min/max across all data.
uint64_t kernel_scalar_stats(std::span<std::span<const float>> data) {
struct stats { float m0=0, m1=0, m2=0; float min=std::numeric_limits<float>::max(), max=-std::numeric_limits<float>::max(); };
stats s;
for (auto block : data)
for (auto d : block) {
s.m0 += 1;
s.m1 += d;
s.m2 += d * d;
if (d < s.min) s.min = d;
if (d > s.max) s.max = d;
}
auto b = [](float f){ return std::bit_cast<uint32_t>(f); };
return b(s.m0) ^ b(s.m1) ^ b(s.m2) ^ b(s.min) ^ b(s.max);
}This hits ~7 GB/s on large blocks—0.75 cycles/byte at 5.7 GHz boost. Other kernels: SIMD stats (faster), popcount, hash. Aggregate hashes to CSV. Code at github.com/solidean/bench-linear-access.
Why control this? Jumps between blocks trigger TLB walks (4 KB pages standard, 2 MB hugepages possible), prefetcher resets, and LLC probes. Prefetchers (hardware stream detectors) excel on linear access but stall on discontinuities. Smaller blocks mean more jumps; slower kernels hide the penalty via amortization.
Why This Matters for Real Code
In HPC or ML inference, data arrives in 64 KB tensors or 4 KB pages. Padding to 1 GB arenas bloats RSS and fragments heaps. These results say: 1 MB chunks suffice for AVX-512 GEMM-like loops. For CPU-bound apps (e.g., compression at 0.1 GB/s), 4 KB works fine.
Compare to GPUs: HBM favors 128 KB+ warps, but CPUs’ deeper hierarchy (L1:32-64 KB, L2:1-2 MB, L3:32-144 MB) tolerates smaller jumps. Test on your iron—ARM Neoverse or Apple M3 might differ due to prefetcher quirks.
Implications: Ditch “one big vector” dogma. Use arenas of 256 KB-1 MB blocks for lock-free queues, sharded hashtables, or batched processing. Saves 50-90% memory vs. over-allocating, scales to NUMA. Peak perf? Yours if you hit these sizes.
One caveat: per-block overheads (e.g., init/teardown) aren’t modeled. For I/O-bound or scatter-gather, add buffer. Still, solid data: linear access rules, but blocks don’t need to be behemoths.