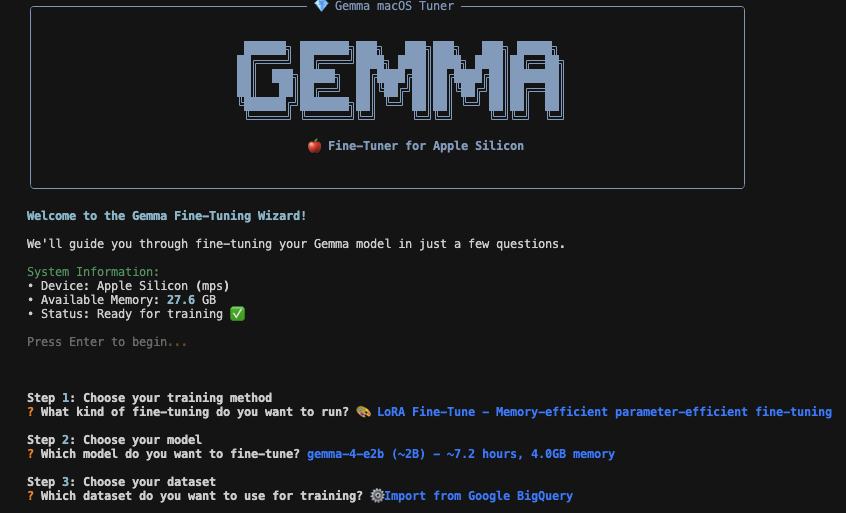
A developer has released an open-source tool to fine-tune Google’s Gemma 4 multimodal model directly on Apple Silicon hardware, like the M2 Ultra Mac Studio. It streams massive datasets—such as 15,000 hours of audio from Google Cloud Storage—without requiring local storage for everything. This sidesteps cloud training costs and privacy risks while working around limitations in Apple’s MLX framework, which doesn’t yet support audio fine-tuning.
The project started six months ago with Whisper, OpenAI’s speech-to-text model. The creator faced a crunch: 15,000 hours of audio sat in GCS, far too large for a local Mac’s drive. They built a streaming pipeline to pull data on-the-fly during training. When Gemma 3n dropped, they integrated it. Gemma 4’s release a few days ago prompted a cleanup and split: one part for Whisper, another for Gemma. The repo now invites forks and improvements.
Technical Breakdown
Training runs locally on the M2 Ultra’s unified memory architecture, which shines for ML workloads. The Mac Studio in question packs 64GB RAM—respectable for a desktop but tight for LLMs. Gemma 4, as a multimodal model handling text, audio, and likely vision, chews through memory on long sequences. Out-of-memory (OOM) errors hit frequently, forcing tweaks like shorter contexts or lower batch sizes.
Why build custom? Apple’s MLX library accelerates models on Metal, but lacks robust audio fine-tuning pipelines. Competitors like Hugging Face’s Transformers or custom PyTorch setups fill the gap, paired with GCS streaming via APIs. Expect dependencies on torch, datasets, and Google Cloud SDK. No code snippets in the announcement, but the GitHub repo (implied via Show HN) should detail setup—likely a pip install -r requirements.txt followed by config for your GCS bucket.
Performance context: M2 Ultra delivers around 30-40 TFLOPS FP16 on GPU cores, competitive with mid-tier NVIDIA A100 slices for fine-tuning. Streaming adds latency—say, 100-500ms per batch depending on bandwidth—but keeps costs under $1/hour vs. $3-10/hour on cloud GPUs. For 15k hours audio, preprocessing alone could cost hundreds in cloud compute; local runs it for electricity only.
Limitations and Realities
Don’t expect miracles. 64GB caps viable batch sizes at 1-4 for Gemma 4’s parameter count (likely 9B-27B range, per Gemma lineage). Longer sequences demand gradient checkpointing or LoRA/QLORA adapters to slash memory—standard tricks, but they slow convergence. No quantization mentioned; 4-bit or 8-bit via bitsandbytes could help, but Apple Silicon favors native FP16.
Skepticism check: Gemma 4 is brand new—Google’s Gemma 2 (9B/27B) launched June 2024 with strong benchmarks (MMLU 82% for 27B). If “4” signals an upgrade, expect similar open weights under permissive license. Multimodal means vision-language-audio potential, but verify repo for exact modalities. Streaming works for GCS; adapt for S3 or local with minimal changes.
Why This Matters
Local fine-tuning democratizes access. Cloud providers charge premiums; AWS/GCP instances for equivalent compute run $5k+ monthly. Apple Silicon users—millions strong—gain a privacy-first path to customize models for niche data like proprietary audio transcripts. Implications ripple: enterprises dodge data exfiltration risks, hobbyists iterate fast without API quotas.
It exposes hardware ceilings. 64GB suffices for prototyping; scale to M3 Max (128GB+) or clusters for production. Broader trend: tools like this accelerate the shift from cloud monopolies. MLX will catch up—Apple invests heavily—but until then, this bridges the gap. Fork it, test on your rig, report OOM fixes. In a hype-drenched AI space, pragmatic builds like this cut through noise.