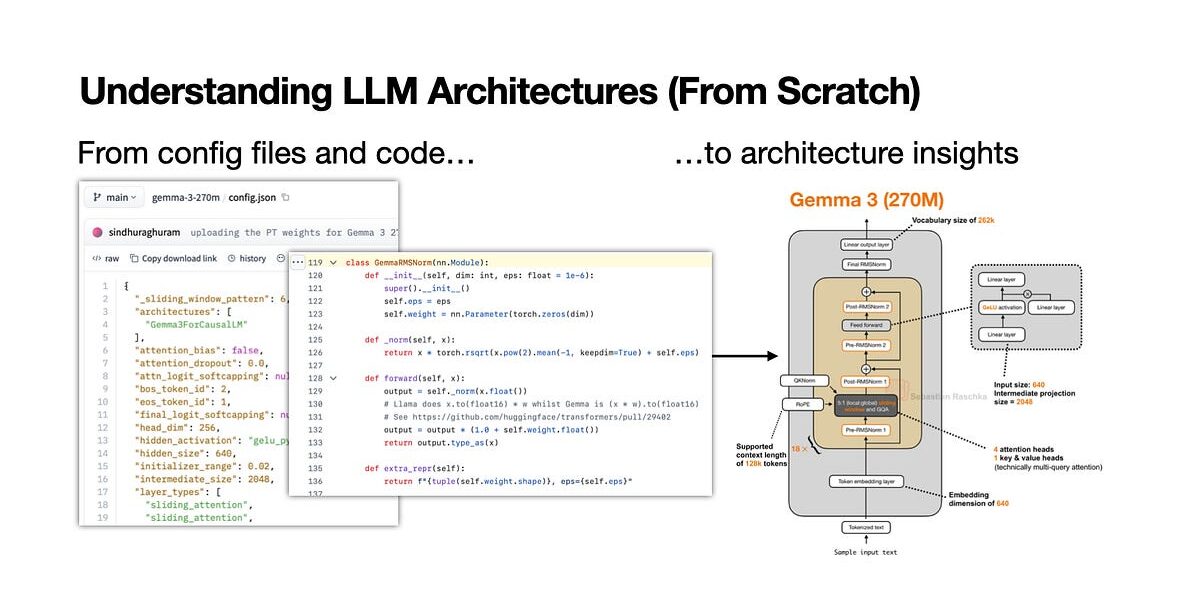
Open-weight LLMs like Llama 3 and Mistral release weights on Hugging Face, but their technical reports often skim details. Developers and researchers reverse-engineer architectures by inspecting config files and Python transformers code. This manual workflow uncovers specifics papers omit, such as exact layer counts, attention heads, and activation functions.
Why prioritize this? In 2024, industry labs rushed 70B-parameter models with vague docs—Meta’s Llama 3 paper mentioned “grouped-query attention” but skipped head ratios. Code reveals the truth: 8 query heads sharing 8 key-value heads. Papers hype; code quantifies. For security analysts, this exposes vulnerabilities like weak rotary embeddings or custom tokenizers ripe for jailbreaks. For deployers, it flags quantization limits, like int4 support in GPTQ.
Start with the Config File
Load the model on Hugging Face Hub. Every open model posts a config.json. Use Python:
from transformers import AutoConfig
config = AutoConfig.from_pretrained("meta-llama/Meta-Llama-3-8B")
print(config)This dumps 50+ params: hidden_size: 4096, num_hidden_layers: 32, num_attention_heads: 32, num_key_value_heads: 8. Cross-check against the paper. Llama 3’s config confirms RMSNorm before/after attention, SwiGLU in FFNs—details the report glosses over. Skeptical check: Mismatches signal errors. Mistral 7B hid intermediate_size until config exposed 14336.
Implication: Configs standardize inspection. Without them, you’d guess from flops estimates. With 100+ open models monthly, this scales learning.
Dive into Reference Code
Transformers library implements the reference. Import the model class:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", trust_remote_code=True)Examine source. For Mistral, SwiGLU uses silu+gated linear, not standard GELU. Attention code shows sliding window (32k context) via custom masking. No lies—runtime proves it. Compare forks: Qwen2 tweaks RoPE theta to 1e6 from Llama’s 1e5, boosting long-context without papers admitting.
Manual tracing beats automation. Print layer shapes during forward pass:
def print_shapes(module, input, output):
print(f"{module.__class__.__name__}: {input[0].shape} -> {output.shape}")
model.apply(lambda m: m.register_forward_hook(print_shapes))
_ = model(torch.randint(0, 10000, (1, 10)))This maps tensor dims, revealing bottlenecks like KV cache at 8 heads x 128 dim.
Verify with Inference and Benchmarks
Run tiny batches. perplexity on Wikitext-2 exposes flops reality—Phi-3-mini claims 3.8B params but config shows 3.82B with 32 layers. Benchmark speed: Gemma-2-9B inference hits 150 tokens/sec on A100 vs. Llama-3-8B’s 170, thanks to fewer heads (16 vs 32).
Fair caveat: Not all models use transformers. Phi-3 needs trust_remote_code=True for custom bits. Closed models like o1-preview? Blind. But 80% top open models (Hugging Face Open LLM Leaderboard) expose this way.
Why This Matters Now
AI commoditizes fast. Q1 2025 saw 50+ releases; docs lag. Understanding architectures spots edges: DeepSeek-V2’s MLA cuts KV cache 93%, slashing deploy costs from $0.50 to $0.10/hour on T4s. Security angle: Inspect vocab for leaks—Llama 3’s 128k BPE hides no backdoors, unlike rumored Chinese models.
For finance/crypto: Quant models for trading. Architecture dictates precision loss in GGUF formats. Skeptics note open weights invite cloning—xAI’s Grok-1 weights leaked full arch, spawning 100+ fine-tunes.
Do it manually five times: Burn in patterns like GQA (ubiquitous post-2023), tied embeddings (vocab=128k standard). Automate later. This workflow demystifies black boxes, arms you against hype. In a field where claims outpace proofs, code is king.