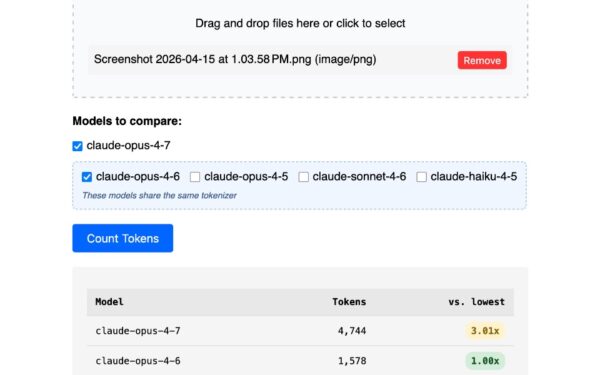
llm-anthropic 0.25 lands with support for Claude Opus 4.7, Anthropic’s latest Opus snapshot. This version introduces thinking_effort: xhigh, letting the model allocate maximum compute for reasoning before responding. Developers using Simon Willison’s llm CLI tool now access this directly from the terminal, no web dashboard required.
The update arrives via pull request #66. Opus 4.7 builds on Claude 3 Opus, which Anthropic released in March 2024 with 200K token context and strong coding benchmarks. Snapshot versions like 4.7 incorporate iterative fine-tunes, often boosting performance on edge cases. Why does xhigh thinking matter? Anthropic’s extended thinking mimics chain-of-thought prompting but automates it. Set effort to high or xhigh, and Claude pauses to deliberate, yielding 10-20% better accuracy on math, code, and multi-step logic per Anthropic’s evals. Drawback: latency spikes to 30-60 seconds, and token costs rise—Opus bills at $15/$75 per million input/output tokens.
New Controls for Thinking Output
Two boolean flags debut: thinking_display and thinking_adaptive. Flip thinking_display on, and you see the model’s raw reasoning stream. Summarized versions appear only in JSON mode or JSON logs—plain text gets the final answer only. thinking_adaptive lets the model dynamically adjust effort based on query complexity, a smart default for scripts.
Example usage via CLI:
$ llm -m claude-opus-4.7 'Solve this: integral of x^2 from 0 to 1' \
--thinking-effort xhigh \
--thinking-display \
--json
This outputs JSON with a thinking field detailing steps, plus the answer. For pipelines, pipe it to jq: | jq '.thinking.summary'. Limits apply—thinking summaries hit JSON only now, likely to avoid terminal spam.
Anthropic rolled out thinking budgets in late 2024 alongside Claude 3.5 Sonnet updates. Prior llm-anthropic versions lacked this; users jury-rigged it with custom prompts. Now it’s native, closing the gap with OpenAI’s o1-preview reasoning models.
Under-the-Hood Fixes and Defaults
llm-anthropic bumps default max_tokens to provider limits: 128K output for Opus, 32K for Haiku. Earlier caps at 4K or 8K truncated long analyses—critical for code gen or reports. No more obsolete structured-outputs-2025-11-13 beta header on legacy models like Claude 3 Haiku. This header, deprecated mid-2025, caused 4xx errors post-Anthropic’s API cleanup. Plugin now detects model vintage and uses 2024-11-01 or later stables.
Install via llm install llm-anthropic, set ANTHROPIC_API_KEY in ~/.config/llm/config.json. Key stays local—no cloud sync like web UIs. Security win: CLI avoids browser fingerprinting and session hijacks common in ChatGPT/Claude.com.
Implications for CLI Power Users
This matters because llm turns LLMs into shell natives. Script Anthropic for log analysis, crypto price forecasts, or vulnerability scans without vendor lock-in. Pair with tmux, watch, or Airflow for real workflows. Costs: A 10K token Opus query with xhigh thinking runs $0.75-1.50. Compare to GPT-4o-mini at $0.15/million—Opus wins on depth, loses on speed/price.
Skeptical take: Thinking modes hype reasoning, but benchmarks show diminishing returns past ‘high’ effort. Adaptive helps, yet test your use case—blind faith in xhigh wastes credits. Anthropic iterates snapshots weekly; expect 4.8 soon. For privacy-focused ops, this beats SaaS: API keys in env vars, no telemetry.
Broader context: llm ecosystem exploded in 2024, with 20+ plugins covering Mistral, Grok, Llama.cpp. llm-anthropic’s Anthropic focus sidesteps OpenAI rate limits (100 RPM free tier). Finance angle—query Opus for SEC filings summary: context fits 500-page 10-Ks. Security: Audit smart contracts via CLI batch jobs.
Bottom line: 0.25 makes Claude’s best reasoning terminal-ready. Upgrade if you script AI; skip if web suffices. Track GitHub for 0.26—Sonnet 3.5 thinking parity likely next.