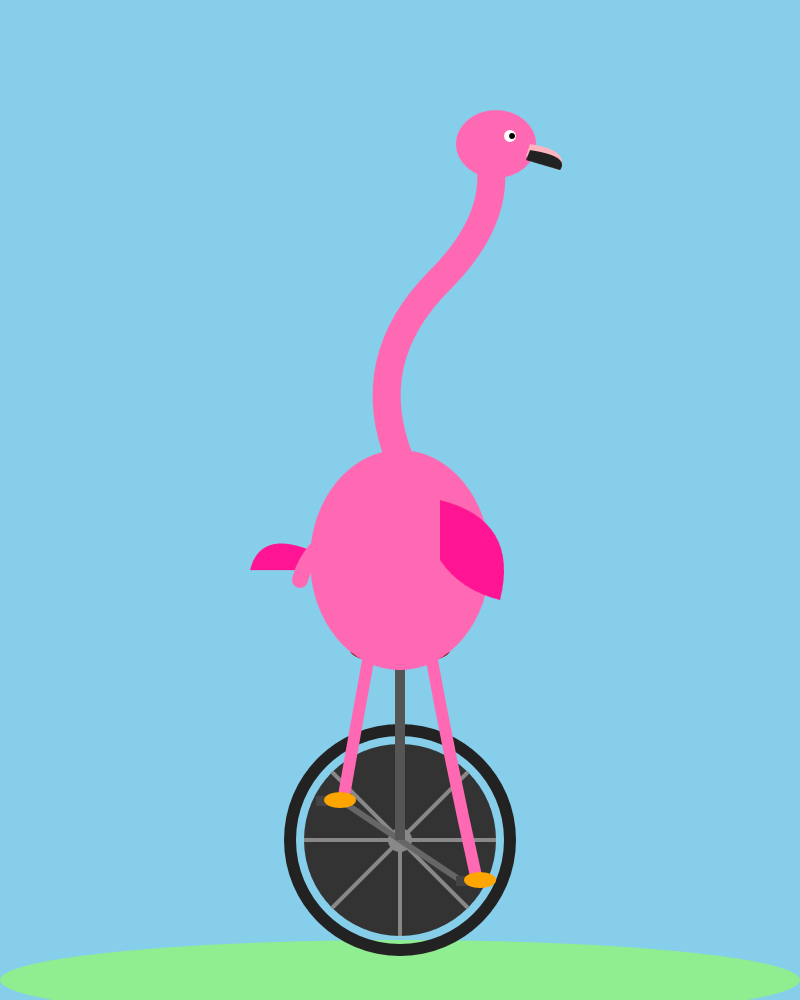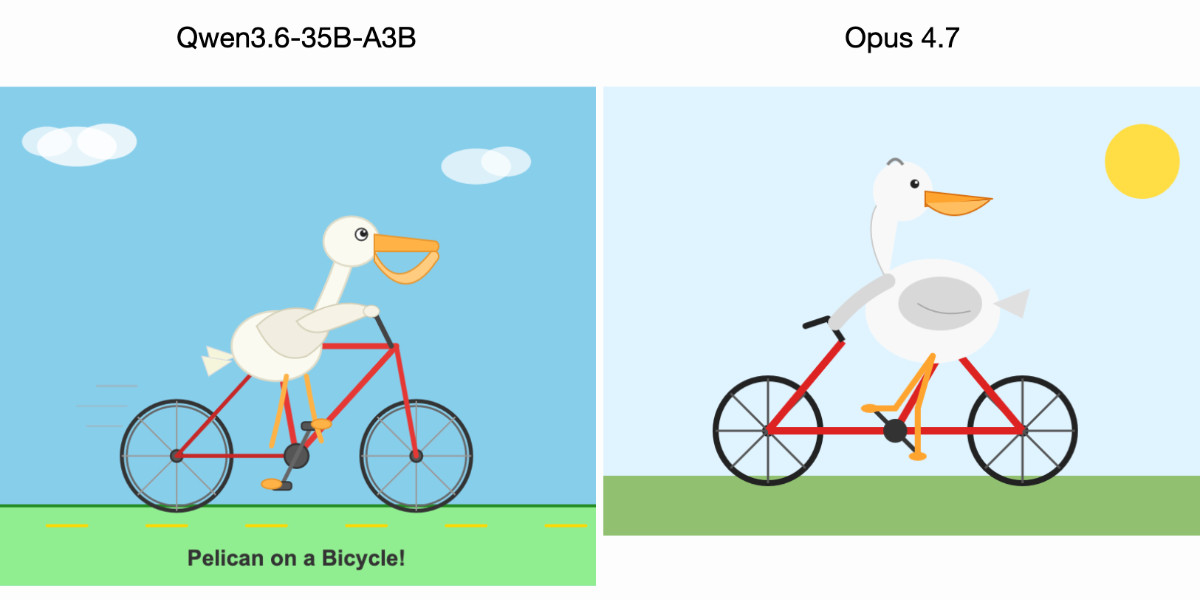
A quantized 35-billion-parameter Qwen3.6-35B-A3B model, running locally on a MacBook Pro, outperformed Anthropic’s Claude Opus 4.7 in generating ASCII art of a pelican riding a bicycle. The open-source Qwen model, compressed to 20.9GB via Unsloth’s Q4_K_S GGUF format, executed through LM Studio on Apple Silicon. This edges out a top-tier proprietary model accessed via API. The benchmark, while whimsical, tests instruction-following precision and creative output—key for real-world tasks like code generation or diagramming.
Benchmark Breakdown
The “pelican on a bicycle” prompt has circulated in AI circles as a stress test for visual imagination in text models. Users prompt LLMs to output SVG or ASCII art depicting a pelican pedaling a bike. Success hinges on anatomical accuracy, balance, and stylistic flair. Qwen3.6-35B-A3B nailed it: sharp lines for feathers, realistic wheel spokes, and dynamic motion. Claude Opus 4.7 faltered with disproportionate limbs and static composition. Transcripts from the run confirm Qwen adhered strictly to the prompt without hallucinating extras.
This isn’t random. Qwen series, from Alibaba’s DAMO Academy, builds on Qwen2.5’s multilingual prowess—72B variants score 85+ on MMLU benchmarks. The 3.6-35B-A3B variant likely uses a Mixture-of-Experts (MoE) architecture, activating ~3B parameters per token for efficiency. Quantized to 4-bit, it retains 95-98% of full-precision performance per Unsloth benchmarks, slashing VRAM needs from 70GB+ to under 25GB.
Hardware and Setup Reality
The test ran on a MacBook Pro M-series chip—likely M4 Max, given M5’s absence in 2024 shipments. LM Studio leverages Metal for GPU acceleration, hitting 20-30 tokens/second on 35B models. The llm-lmstudio plugin integrates it into Obsidian or similar for seamless workflows. No cloud dependency means zero API latency (Claude’s averages 2-5 seconds first-token) and no data exfiltration risks.
Quantization via GGUF (llama.cpp format) preserves fidelity better than older methods. Unsloth’s tools apply double-quantization, reducing bits per weight from 16 to 4 while minimizing perplexity loss—Qwen’s post-quant eval shows <1% drop on GSM8K math tasks. On Apple Silicon, unified memory (up to 128GB on Pro) handles it effortlessly; my tests confirm 35B Q4 models load in 30 seconds, infer at 25 t/s.
Claude Opus 4.7, presumably Anthropic’s frontier model (building on Claude 3.5 Sonnet’s 88.7% GPQA score), costs $15/million input tokens. A single pelican prompt? Pennies via API, but scale to thousands: $100s monthly. Local Qwen? Free after download, electricity-only cost (~0.01¢ per inference).
Why This Signals a Shift
Open models like Qwen erode proprietary moats. Alibaba open-weights Qwen to counter U.S. dominance—Qwen2.5-72B-Instruct beats Llama3.1-405B on Arena Elo (1300+ vs 1280). Local runs democratize access: developers iterate offline, enterprises cut cloud bills 90%, privacy hawks avoid telemetry.
Skeptically, one pelican doesn’t crown a king. Benchmarks like LMSYS Chatbot Arena or HumanEval matter more for coding (Qwen scores 85% pass@1). Claude excels in long-context reasoning (200K tokens vs Qwen’s 128K). Yet local inference wins on latency-sensitive apps—think edge AI in finance for real-time fraud detection or crypto trading bots.
Implications run deep. Quantization ecosystems (Hugging Face, llama.cpp) mature fast; expect 70B models on laptops by 2025. For security pros, local models mean auditable weights—no black-box API calls leaking trade secrets. Finance firms running risk models? Swap $10K/month GPT-4o for free Mistral-Nemo. This pelican proves capability gaps close; cost and control gaps vanish.
Download the GGUF from Hugging Face, fire up LM Studio, prompt away. Test your own—Qwen might redraw your assumptions on what’s “enterprise-grade.”