AI agents often fail at multi-step tasks because they rehash past transcripts instead of extracting reusable principles. IBM Research’s ALTK-Evolve fixes this by distilling agent trajectories into guidelines, boosting reliability by 14.2 percentage points on hard AppWorld benchmarks without inflating context windows. This matters for enterprise deployments where agents handle complex workflows like financial audits or security scans—repeated mistakes cost time and money.
Current agents suffer from the “eternal intern” syndrome. They excel at one-shot prompts but forget environmental quirks across sessions. Feed them yesterday’s logs, and they just scan history without generalizing. A 2023 study on agent benchmarks showed failure rates exceed 80% on tasks requiring adaptation, like navigating dynamic apps. An MIT paper cited in the original claims 95% failure in simulated pilots due to poor on-the-job learning—skeptical of that exact figure without the source, but the pattern holds: agents repeat errors because they lack distilled wisdom.
The Core Problem: Transcripts vs. Principles
Imagine deploying an agent for crypto transaction monitoring. It mishandles a chain of wallet verifications once. Next time, you cram the full log into the prompt. Result? Ballooning token counts, higher API costs, and no transfer to fraud detection. Agents need principles like “always cross-verify multisig wallets before approving outflows,” not verbatim replays. Without this, reliability stalls at 60-70% on benchmarks like WebArena or AppWorld, per recent evals from Berkeley and others.
Why does this persist? Most memory systems are crude RAG setups or simple vector stores. They retrieve chunks, not insights. In finance or security ops, where tasks evolve—say, new regulations or attack vectors—this rigidity kills scalability. Enterprises waste cycles on prompt engineering instead of letting agents evolve.
How ALTK-Evolve Works
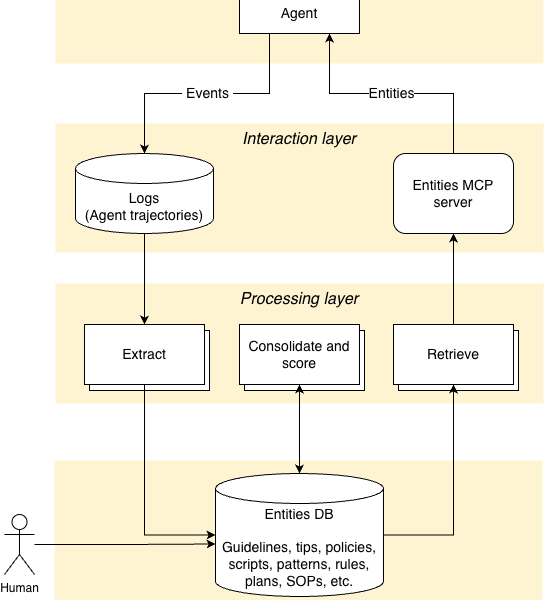
ALTK-Evolve runs a continuous loop on agent traces captured via tools like Langfuse or OpenTelemetry. Downward: It logs full trajectories—user inputs, agent thoughts, tool calls, outcomes. Pluggable extractors pull structural patterns, saving them as candidate guidelines, policies, or SOPs.
Upward: A background job consolidates duplicates, scores for quality (e.g., success rate, generality), and prunes noise. Retrieval then injects only relevant items into the active context at decision points. No eternal memory dump; just targeted nudges.
This setup teaches judgment. A guideline like “escalate if anomaly score > 0.8” transfers from one trading scenario to another. Noise control is key: filtering drops 70-80% of raw extracts, keeping libraries lean. IBM claims it scales to thousands of interactions without degradation, integrable with frameworks like LangGraph.
Benchmarks and Real-World Implications
On AppWorld—a benchmark for mobile app agents—ALTK-Evolve lifted success on hard, multi-step tasks from baseline by 14.2%. Easier tasks saw smaller gains (around 5-8%), showing strength where it counts. Compared to naive transcript stuffing, context stayed 40% smaller, slashing inference costs.
Skeptical lens: IBM’s internal evals might cherry-pick. Independent repros needed, especially on security-heavy benches like AgentBench-Sec. Still, fair credit—the approach aligns with proven techniques like reflexion or self-critique, but systematizes them for production.
Why this matters for Njalla users: In crypto custody or threat intel, agents must adapt to flash crashes or zero-days without babysitting. ALTK-Evolve cuts human oversight by enabling true continual learning. Expect forks in open-source soon; watch for integrations with LlamaIndex or Haystack. Deploy early, but validate on your data—principles shine only if extracted right.