Nathan Lambert just dropped the ATOM Report, a data-packed analysis of the open language model ecosystem. Released alongside the ATOM Project’s manifesto pushing U.S. investment in open models, this arXiv paper (2604.07190) tracks downloads, inference market share, and adoption trends. It highlights GPT-OSS’s surge, China’s mid-tier players like Moonshot, Z.ai, and MiniMax grabbing ground, and early U.S. progress. Why does this matter? Closed models from Big Tech centralize power; open ones enable scrutiny, customization, and resilience against censorship or failures. In security terms, auditable weights beat black boxes every time.
Relative Adoption Metric Cuts Through the Noise
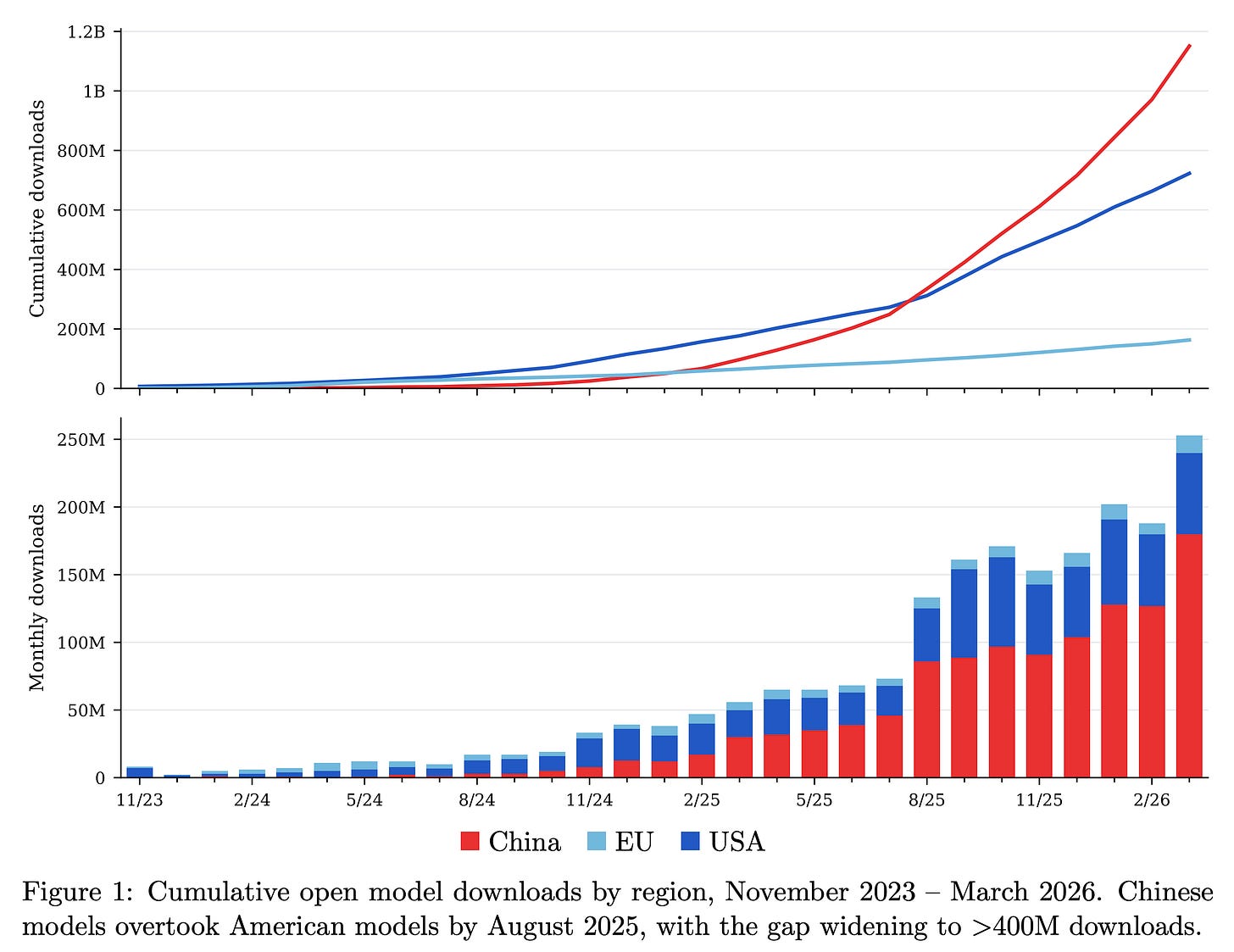
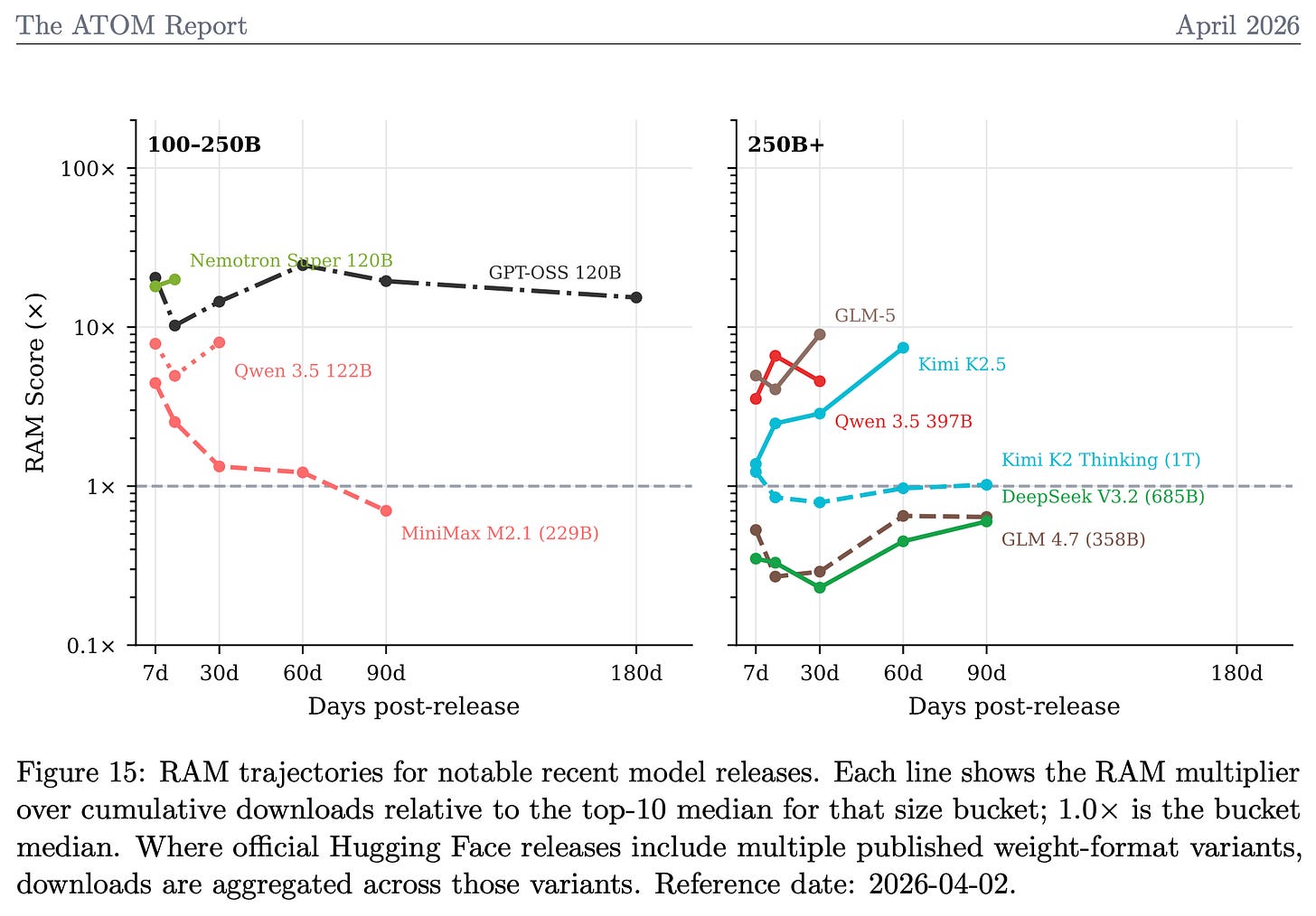
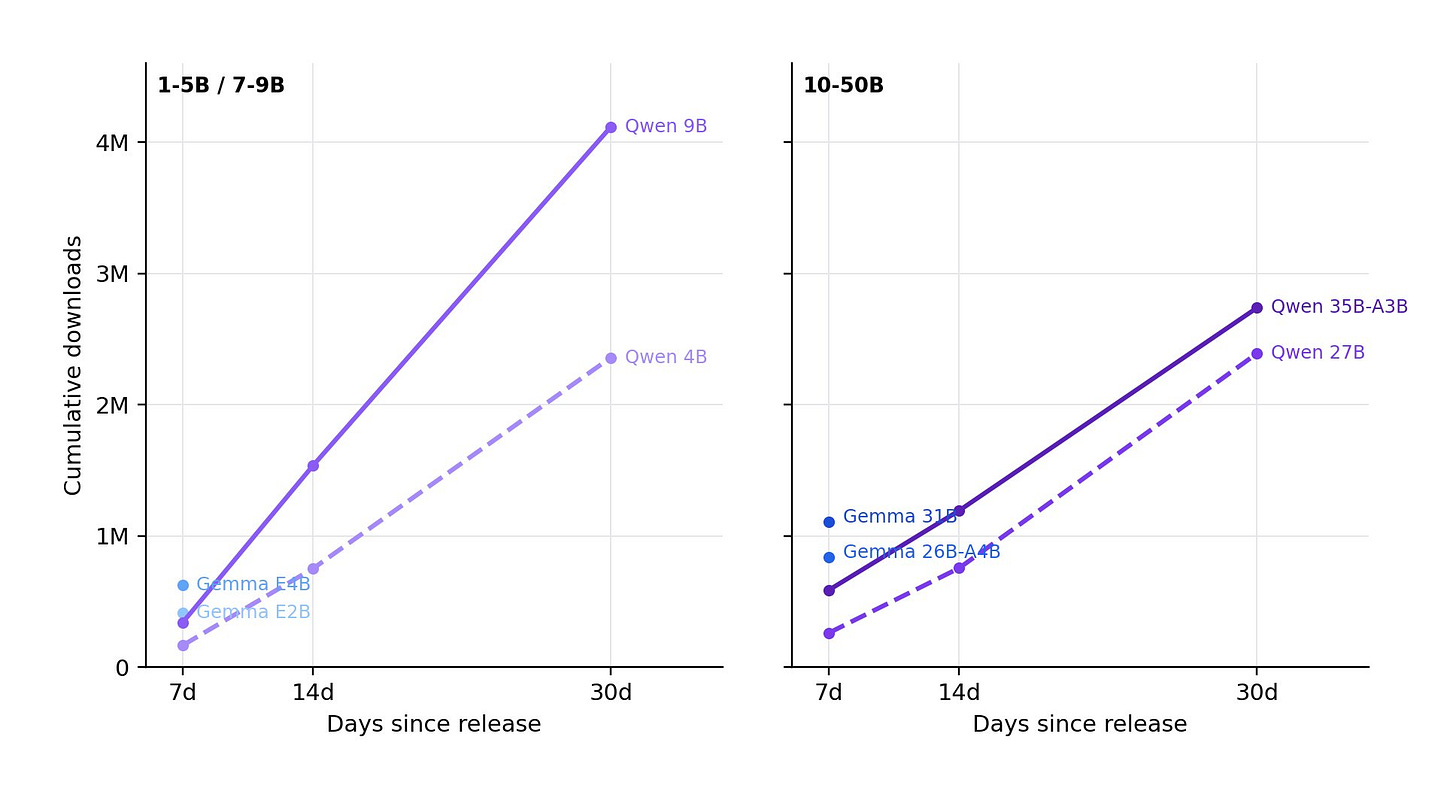
The report’s star is the updated Relative Adoption Metric (RAM), which normalizes downloads by model size and time. A RAM score over 1 flags a model on pace to crack the top 10 ever for its category. Recent Chinese releases dominate the charts, signaling fierce competition. Google’s Gemma 4 shows explosive early traction too. Lambert and Florian Tramèr built this to simplify a chaotic field—Hugging Face stats alone span thousands of models.
Skeptical take: Metrics like RAM help, but downloads don’t equal quality or real-world use. Inference share matters more for deployment costs and scalability. Still, it exposes gaps—U.S. open efforts lag despite hype. Implications? Policymakers and investors should watch China’s output; it pressures closed players like OpenAI while offering alternatives less prone to shutdowns. Subscribe to ATOM’s Substack for updates, but verify the data yourself.
RLHF Book Targets Post-Training Gap
Lambert finished his RLHF book after starting seriously in May 2024. Sent to Manning for production last week (as of April 2026), it hits print in two months. Pre-order now on Amazon or Manning—the latter’s cheaper. Aimed at bridging beginner-to-expert in post-training (RLHF, DPO, etc.), it fills a void as base models commoditize. No fluff: This is the handbook he wanted when diving in.
Why care? Post-training alignment turns raw LLMs into usable tools, but it’s underdocumented. Proprietary methods from Anthropic and OpenAI stay secret; open recipes democratize it. Security angle: Better alignment reduces jailbreaks and biases, critical for enterprise or crypto apps. Pair it with the code repo he’s building—expect GitHub drops soon.
Post-Training Course Builds Community
To extend the book, Lambert’s launching free YouTube lectures at rlhfbook.com/course. Not beginner basics—these assume base model knowledge and target practitioners scaling to production. Community forums will follow, fostering collaboration as AI shifts from pre-training arms races to fine-tuning efficiency.
This matters because talent pipelines lag. With Llama 3 and Mistral iterating fast, experts in reward modeling or PPO are bottlenecks. Free resources lower barriers, especially outside Silicon Valley. Fair critique: YouTube lectures risk superficiality without hands-on labs, but the book’s code integration could fix that.
Ongoing research fills out Lambert’s plate—Interconnects newsletter hints at deeper dives. Broader context: Open ecosystem hit 40% inference share in spots by late 2025 (per reports), but U.S. policy stalls on export controls hurting chips. ATOM pushes back, arguing open models bolster national security via diversity. Track RAM for bets: High scorers like Gemma 4 could disrupt paid APIs, slashing costs 10x via self-hosting. Investors, note the Chinese wave—Moonshot’s v1.5 rivals GPT-4o on benchmarks at fraction of price.
Bottom line: Lambert’s output spotlights open AI’s momentum. It challenges closed monopolies, empowers builders, and flags geopolitical shifts. Dig into the report; the numbers don’t lie.