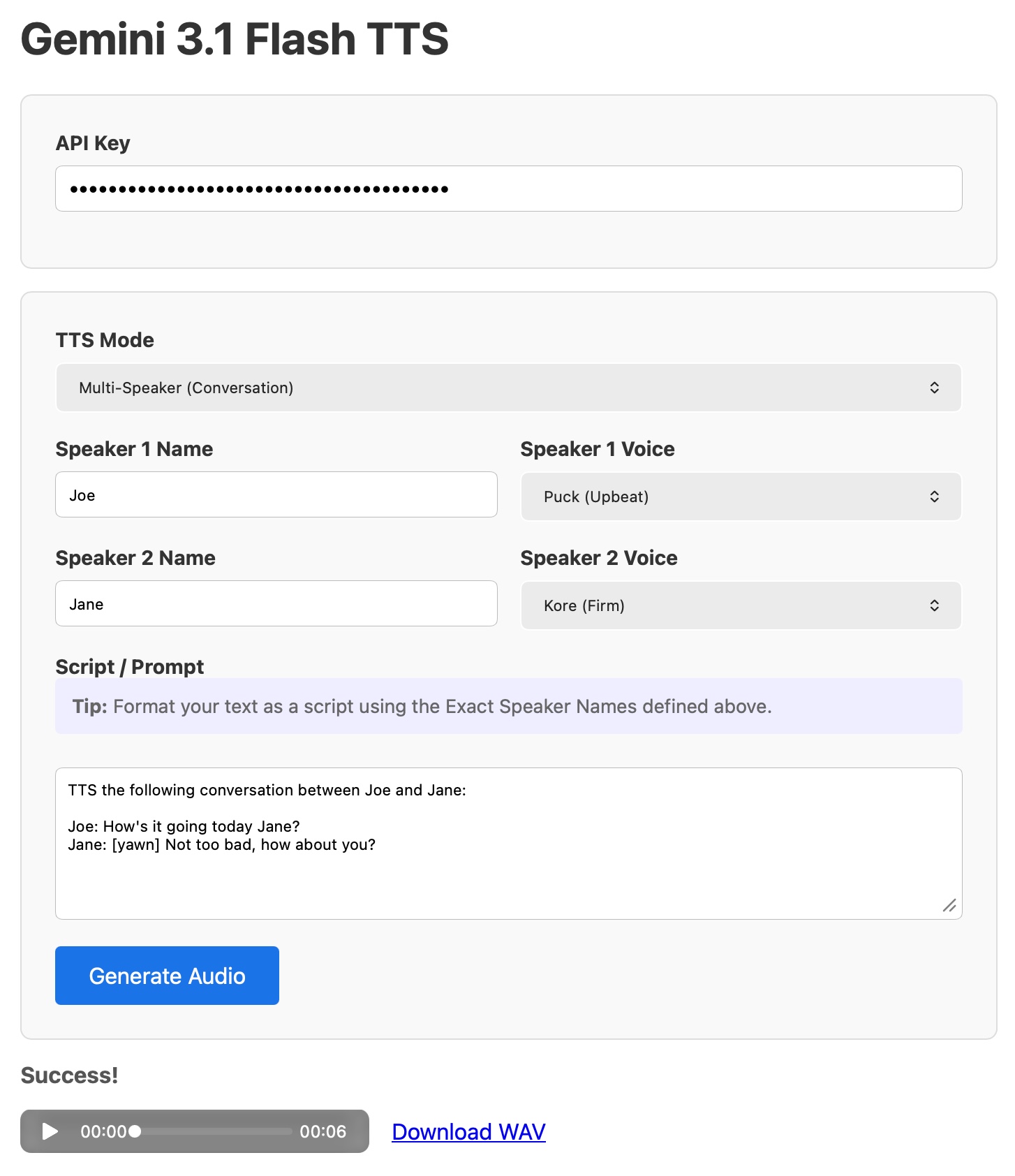
Google launched Gemini 3.1 Flash TTS in preview today. Developers access it through the standard Gemini API using the model ID gemini-3.1-flash-tts-preview. This text-to-speech system responds to natural language prompts that dictate voice style, emotion, and scene details. It generates audio files only—no text transcripts.
The release targets builders needing dynamic voice synthesis without custom voice training. Flash models prioritize speed and cost-efficiency, building on Gemini 1.5 Flash’s low-latency design. Google positions this as a step toward more expressive TTS, but early examples reveal clunky prompting requirements.
Prompts demand a scripted format, far from simple instructions. Google’s sample for a short radio-style segment reads like a film script:
# AUDIO PROFILE: Jaz R.
## "The Morning Hype"
## THE SCENE: The London Studio
It is 10:00 PM in a glass-walled studio overlooking the Thames. City lights flicker below. Jaz R., a British female DJ in her 30s with a husky, energetic voice, leans into the mic. She speaks with London swagger, rising excitement, and playful banter.This verbosity—describing time, location, voice traits, and delivery—produces just seconds of audio. Simpler prompts might work, but Google emphasizes structure for consistency. Why? LLMs like Gemini interpret vague instructions poorly, leading to erratic outputs. Expect iteration counts in the hundreds of tokens just for setup.
API Access and Code
Integrate via the Gemini API’s generateContent endpoint. Specify audio MIME types like audio/mp3 or audio/wav in the response. Here’s a Python example using the official SDK:
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel('gemini-3.1-flash-tts-preview')
prompt = """# AUDIO PROFILE: [Your detailed profile here]
[Full scene and text]"""
response = model.generate_content(
prompt,
generation_config={
"response_mime_type": "audio/mp3"
}
)
with open("output.mp3", "wb") as f:
f.write(response.parts[0].media.data)
Rate limits apply per Google’s tiers: free tier caps at 15 RPM, paid scales to thousands. Audio length limits hover around 30-60 seconds per call, based on Flash precedents. No public benchmarks yet on latency or quality metrics like MOS scores.
Strengths, Weaknesses, and Risks
Strengths shine in customization. Describe any accent, mood, or persona—British DJ, weary CEO, excited narrator—and Gemini approximates it without proprietary datasets. This undercuts services like ElevenLabs, which charge per character and require voice cloning uploads. Google’s API pricing starts at $0.075 per million input tokens, potentially cheaper for high volume.
Skepticism tempers the hype. Verbose prompts inflate costs and slow iteration. Competitors like OpenAI’s TTS-1 HD deliver crisp, natural speech with one-liners: “Speak as a pirate.” Early testers report Gemini’s output as “robotic in edges,” lacking ElevenLabs’ prosody finesse. As a preview, expect API instability and evolving docs.
Why this matters: Promptable TTS floods apps with synthetic voices. Podcasts, virtual assistants, and games gain lifelike narration on demand. Developers bypass voice actor fees—ElevenLabs clones cost $1-5 per voice, plus usage.
Security implications loom large. Njalla tracks voice deepfake surges: 2024 saw 3x rise in audio scams, per FTC data, netting $12B losses. This tool enables instant fraud voices—no training data needed. Pair with Gemini’s vision for video deepfakes, and phishing escalates. Banks and exchanges should audit voice biometrics now; multi-factor trumps audio alone.
Finance angle: Algo traders script earnings calls with biased tones, nudging markets. Crypto projects fake influencer endorsements. Regulators lag—EU AI Act classifies high-risk TTS, but enforcement starts 2026.
Bottom line: Gemini 3.1 Flash TTS previews flexible synthesis at scale. Devs grab API keys today for prototypes. Monitor for general availability; full benchmarks will decide if it disrupts or fizzles. Google’s edge? Ecosystem integration with Android and Workspace. But until prompts slim down, it’s power best wielded by patient engineers.