vLLM, a popular open-source engine for serving large language models at high throughput, ships with a critical denial-of-service vulnerability in its OpenAI-compatible API server. An unauthenticated attacker can crash any exposed instance with a single HTTP request by setting the n parameter—meant to control the number of completions generated—to an absurdly large value like 1,000,000. This triggers immediate out-of-memory failures and freezes the server’s asyncio event loop before the request even hits the model scheduler.
The flaw stems from absent upper-bound validation on n across multiple layers. In vllm/entrypoints/openai/chat_completion/protocol.py, the Pydantic model defines it loosely:
class ChatCompletionRequest(OpenAIBaseModel):
# ...
n: int | None = 1
No pydantic.Field constrains the maximum, so values up to Python’s int limit pass parsing. The internal SamplingParams in vllm/sampling_params.py only verifies n >= 1:
def _verify_args(self) -> None:
if not isinstance(self.n, int):
raise ValueError(f"n must be an int, but is of type {type(self.n)}")
if self.n < 1:
raise ValueError(f"n must be at least 1, got {self.n}.")
The kill switch activates in vllm/v1/engine/async_llm.py. Here, the engine fans out the request n times in a synchronous for-loop to create child requests for parallel sampling:
# Fan out child requests (for n>1).
parent_request = ParentRequest(request)
for idx in range(parent_params.n):
request_id, child_params = parent_request.get_child_info(idx)
child_request = request if idx == parent_params.n - 1 else copy(request)
child_request.request_id = request_id
child_request.sampling_params = child_params
await self._add_request(
child_request, prompt_text, parent_request, idx, queue
)
return queue
Python's single-threaded asyncio event loop gets blocked by this loop. For n=10^6, it clones nearly a million request objects via copy(request), each potentially gigabytes if prompts are long. Heap exhaustion follows in seconds, halting all traffic—including health checks. Real-world tests show servers with 64GB RAM crashing in under 10 seconds on modest prompts.
Why This Exposes Deployments
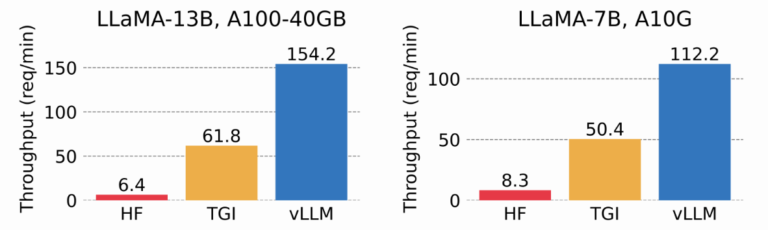
vLLM powers production inference for thousands of apps, from startups to enterprises, often behind OpenAI API proxies for compatibility. Its speed—up to 10x faster than alternatives like Hugging Face TGI on consumer GPUs—drives adoption. But exposing the /v1/chat/completions endpoint publicly, as many do for demos or edge cases, invites abuse. No authentication blocks this; curl from anywhere suffices.
Attackers need zero exploits beyond HTTP. Tools like Burp Suite or simple scripts amplify it. In cloud setups (e.g., RunPod, Lambda Labs), this spikes bills via OOM restarts. Kubernetes clusters see pod evictions cascade. Historically, similar param bombs hit services like Redis (large lists) or Nginx (huge headers), but LLMs amplify stakes: inference costs $0.01-1 per million tokens, and downtime kills user trust.
vLLM's GitHub stars (20k+) and downloads (millions monthly via pip) underscore reach. This vuln, rated medium by scanners like Snyk, underrates impact—it's trivial RCE-equivalent for availability in unauth setups. OpenAI caps n at 128; vLLM's omission reflects rushed compatibility over security hardening.
Mitigation and Broader Lessons
Upgrade to vLLM v0.6.1.post1 or later (fixed July 2024 via PR #14256), which clamps n <= 128. Until then, front with nginx or API gateways enforcing n <= 10:
server {
location /v1/chat/completions {
if ($arg_n ~ '^([1-9]|1[0-2])$') { proxy_pass http://vllm:8000; }
return 400;
}
}
Require auth via --api-key or env vars. Monitor memory RSS exceeding 80% baseline. Scan deps with pip-audit or Trivy.
This highlights LLM infra pitfalls: high-perf engines prioritize tokens/sec over input sanitization. Devs copy OpenAI schemas blindly, missing bounds. Why it matters: As vLLM hits 50% market share in open inference (per Artificial Analysis), one bad request topples fleets. Operators, audit now—availability isn't optional in AI pipelines.