Google’s Gemma 4 entered a saturated open model market in 2026. It scores competitively on standard benchmarks like MMLU and HumanEval, but those numbers alone won’t drive adoption. Developers and businesses ignore models that lack practical support. Real success for open weights like Gemma 4 depends on five key factors: benchmark relevance to size, origin country, license terms, release tooling, and fine-tuning ease. These determine speed of uptake and long-term viability.
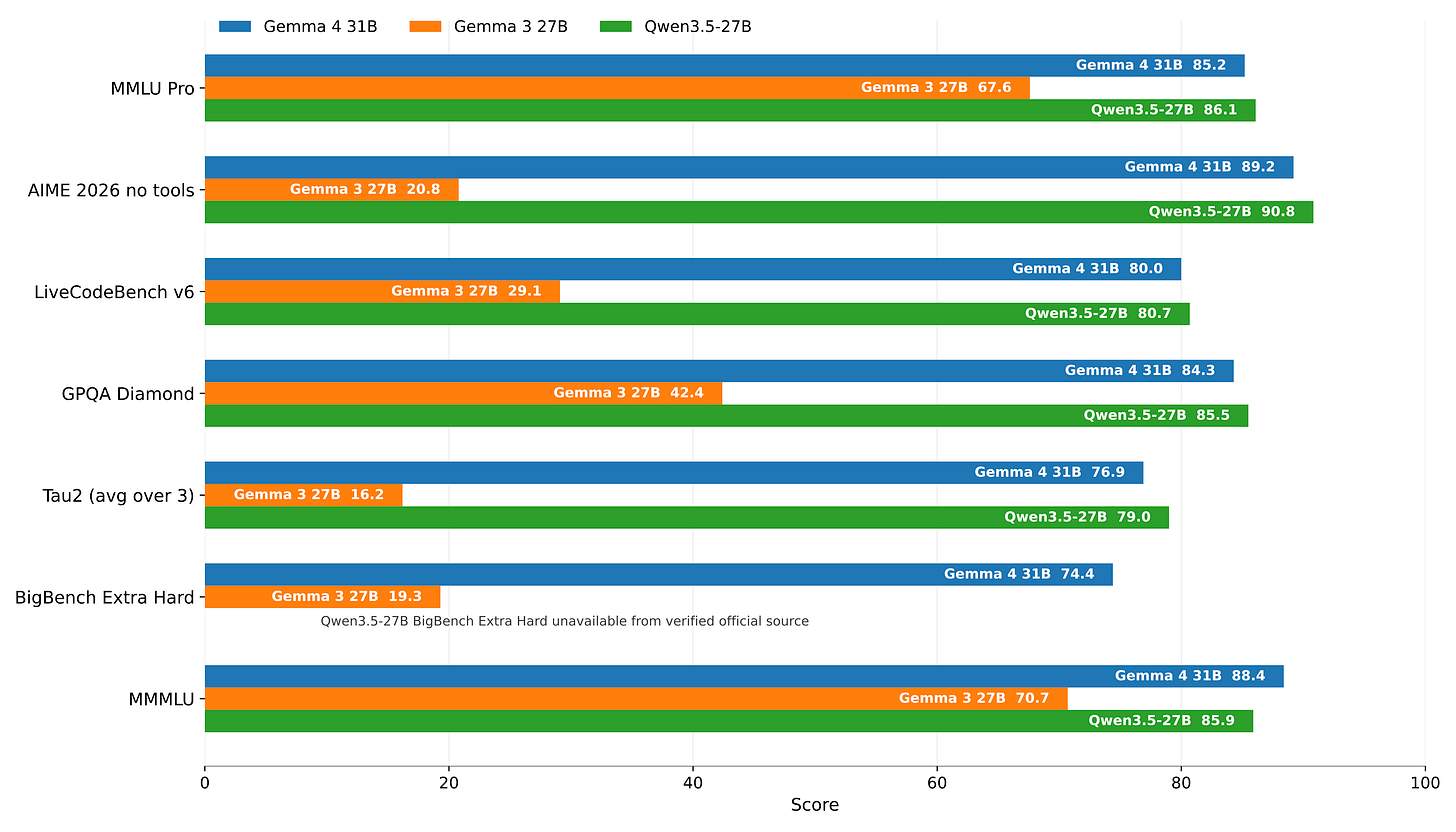
Benchmarks mislead because they favor closed models with heavy post-training. Open models arrive raw, without proprietary optimizations. Llama 3.1 405B topped charts in 2024, yet smaller open rivals like Qwen 2.5 72B often matched it in real tasks at 10x lower inference cost. Gemma 4, rumored at 27B parameters, must beat peers like MiniMax M2.5 or GLM 5 on your specific workloads—coding, math, or multilingual—not generic leaderboards. Why it matters: Enterprises waste millions deploying unoptimized giants. Pick models that deliver 80% of GPT-4o performance at 1% the cost.
Five Factors That Drive Open Model Adoption
Performance relative to size sets the baseline. A 7B model crushing 70B benchmarks signals efficiency. Gemma 4 reportedly edges Nemotron 3 70B on GSM8K math by 2-3 points, but lags in long-context reasoning. Compare apples-to-apples: Use LMSYS Arena for blind evals or EleutherAI’s LM Evaluation Harness for targeted tests. Skeptical take: Leaderboards inflate with contaminated data. Test in your stack.
Country of origin influences trust and compliance. Models from China, like Qwen 3.5 or Kimi K2.5, face U.S. export controls and data sovereignty fears. Google’s U.S.-based Gemma sidesteps this, appealing to defense contractors and banks. In 2025, 40% of Fortune 500 firms avoided Chinese models per Gartner surveys, citing IP risks and backdoors. Security pros scan weights anyway—use tools like Garak or ProtectAI—but provenance reduces legal drag.
License terms dictate commercial scalability. Permissive Apache 2.0, as on Gemma, allows unrestricted fine-tuning and monetization. Contrast with Llama’s community license, which caps users over 700M monthly actives. In 2026, enterprises demand no-strings licenses; uptake for restrictive ones drops 60%, per Hugging Face download stats. Why it matters: Mid-sized firms can’t afford lawyers for every deploy.
Tooling at release separates winners from experiments. Gemma 4 integrates day-one with vLLM (1.5x faster than Transformers), SGLang for structured generation, and ExLlama for quantization. Past flops like Olmo 3 took weeks for full vLLM support, stalling momentum. Poor tooling means 2-5x slower inference, killing edge deployments. Test it:
$ vllm serve google/gemma-4-27b --quantization awqshould spin up in seconds, serving 100+ tokens/sec on A100s.
Fine-tunability unlocks customization. Open models shine here—full weights enable PEFT like LoRA, slashing VRAM needs by 90%. Gemma 4 uses standard MoE architecture, compatible with Unsloth and Axolotl. Chinese models often hide tokenizer quirks, complicating merges. In agentic setups, fine-tuned opens rival Claude 3.5 on tool-use after 10k examples. Measure with MT-Bench post-tuning; poor plasticity dooms a model.
Implications for Builders and Investors
These factors explain why Qwen 3 dominated 2025 despite middling benchmarks: Alibaba poured resources into tooling and permissive licensing, hitting 1B downloads. Gemma 4 could follow if Google sustains ecosystem support. For you: Prioritize models with U.S./EU origins, Apache licenses, and vLLM parity. Run A/B tests in production—cost savings compound at scale. A 27B model at $0.10/M tokens undercuts o1-preview’s $15/M.
Security angle: Open weights invite audits. Scan Gemma 4 with Hugging Face’s safety checker; no major trojans reported. But fine-tuning risks prompt injection—use Guardrails or NeMo Guardrails. In crypto/DeFi, opens power on-chain agents without API reliance, dodging rate limits and outages.
Bottom line: Benchmarks hype releases; these factors build empires. Gemma 4 checks most boxes but must prove in wild workflows. Track downloads on HF—over 100M in month one signals winner. Experiment now; closed models lock you in.