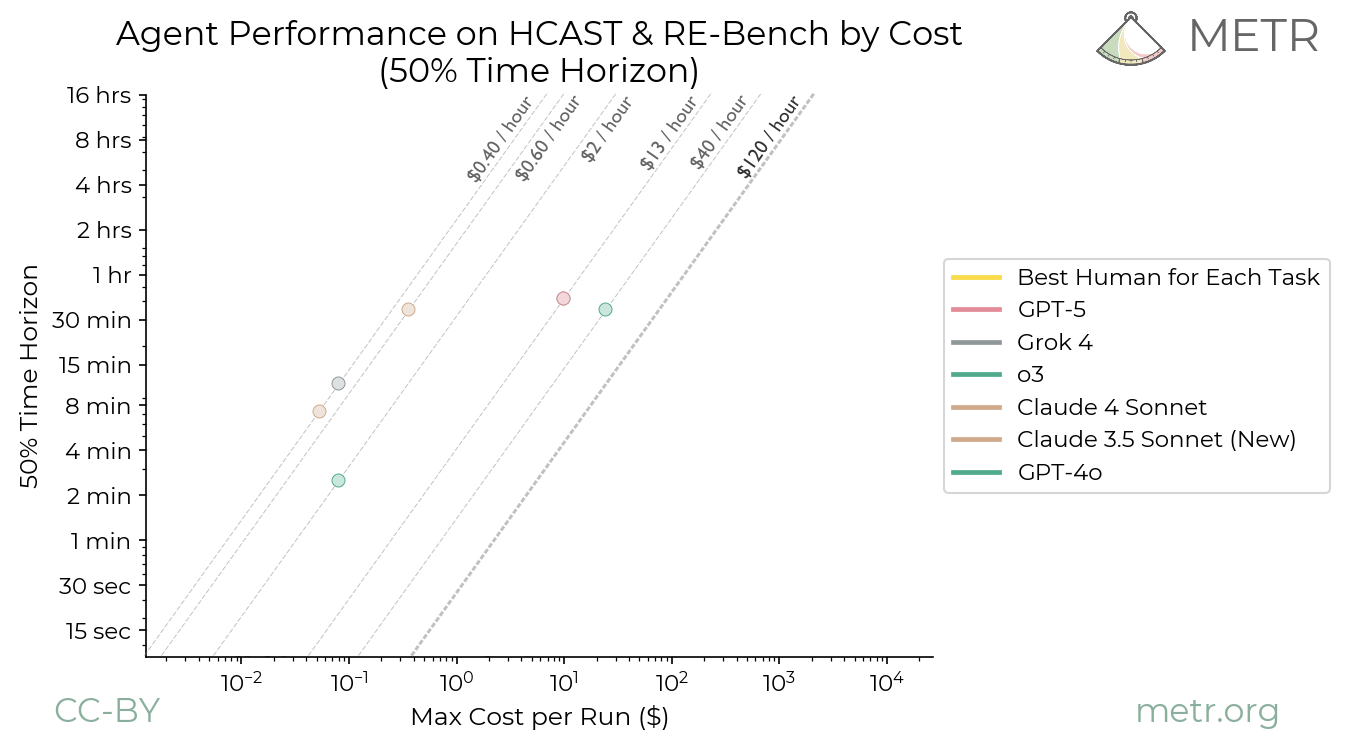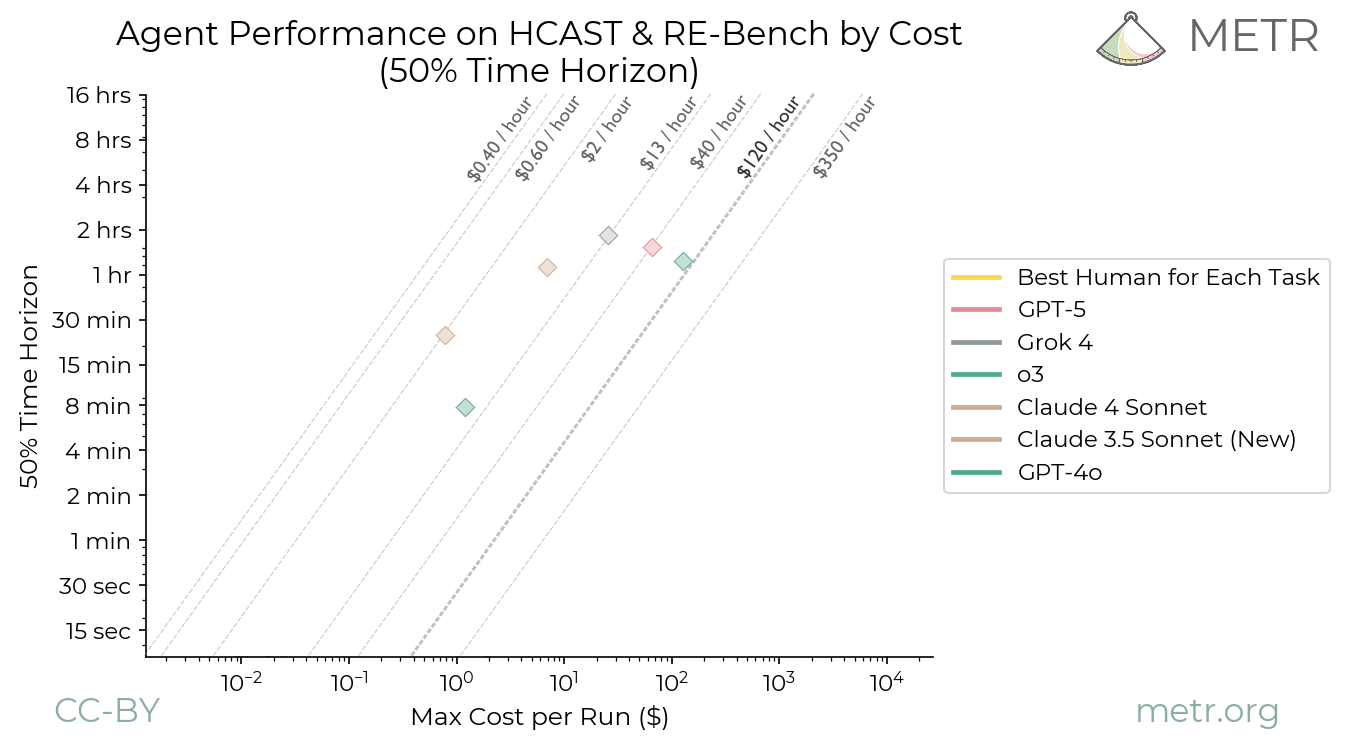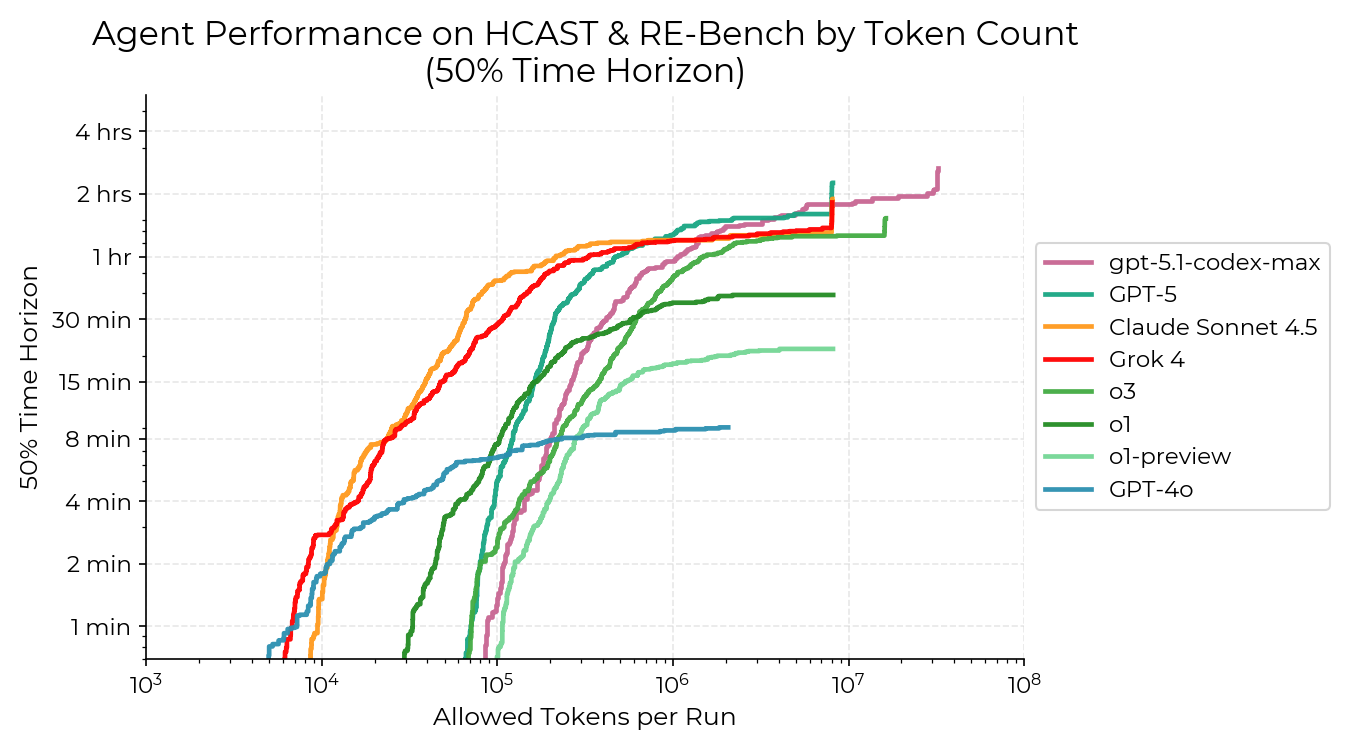
AI agent costs aren’t rising exponentially across the board. Inference prices for large language models continue to plummet—OpenAI slashed GPT-4o rates to $2.50 per million input tokens and $10 per million output tokens by mid-2024, a 50% drop from GPT-4 Turbo. Yet for autonomous agents chaining multiple calls, looping through tools, or running in real-time, expenses stack up fast. A Hacker News thread sparked by Epoch AI data questions if this leads to runaway costs by 2025. The answer: not exponential growth in base compute, but linear explosion from agent designs that burn tokens relentlessly.
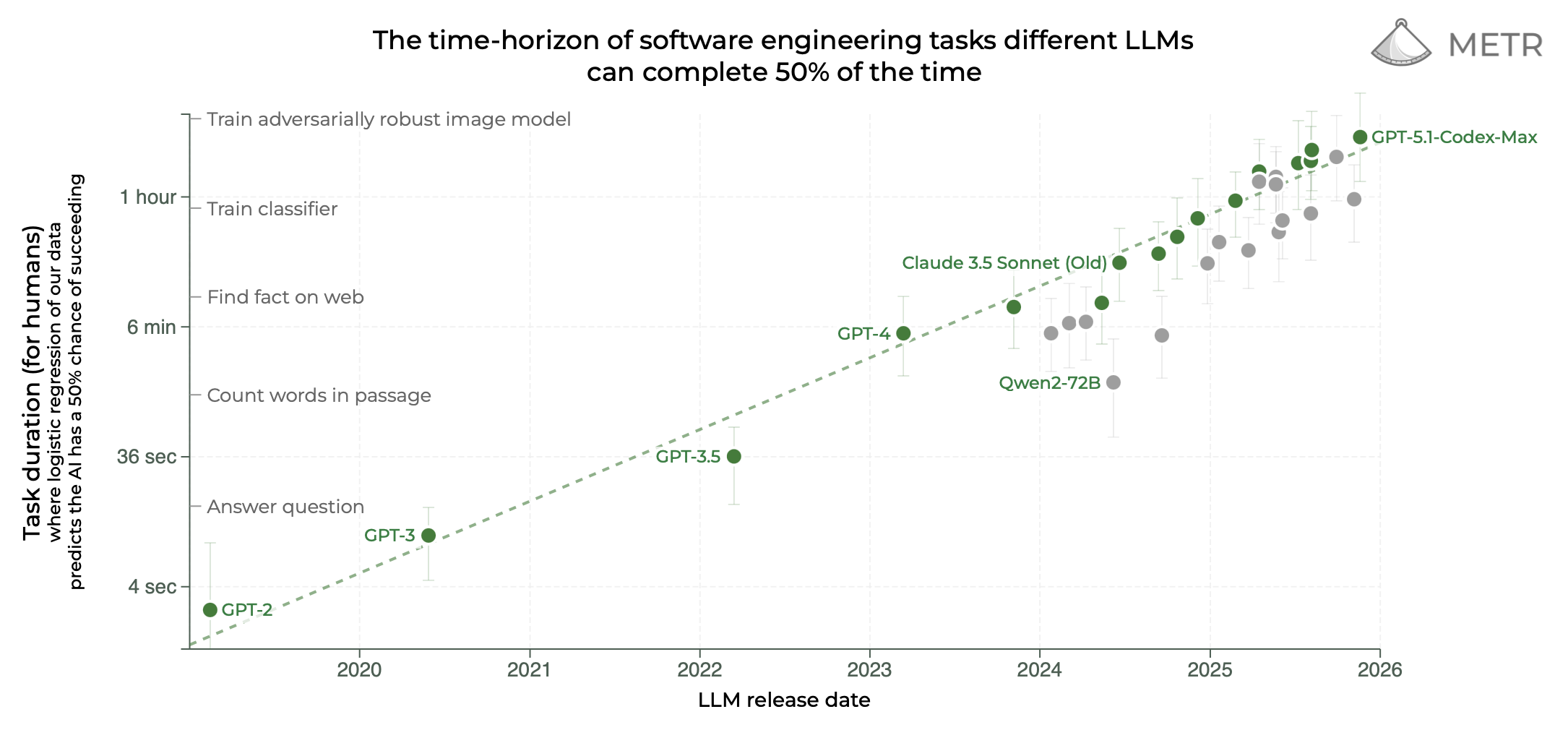
Training costs for frontier models do scale exponentially. Epoch AI tracks machine learning compute doubling every 6.1 months since 2010, pushing GPT-4’s bill past $100 million in 2023. Rumors peg potential GPT-5 training at $1-10 billion, fueled by 100,000+ NVIDIA H100 GPUs at $30,000-40,000 apiece, plus $500k+ annual data center power per rack. But agents rely on inference, not retraining. Providers optimize here: Grok-2 inference runs 3x cheaper than GPT-4 on xAI’s Colossus cluster of 100,000 H100s. Mistral’s open models hit $0.20 per million tokens on spot instances.
Agents Multiply the Bill
Agents like Devin (Cognition Labs) or Anthropic’s Claude with computer use turn one query into dozens. Devin reportedly racks up $1,000+ per complex coding task via 10,000+ tokens across reasoning loops, web searches, and code execution. Multi-agent systems, hyped for 2025—like swarms in AutoGen or CrewAI—coordinate 5-20 LLMs per workflow. Run that 24/7, and a single agent costs $40,000 monthly on GPT-4o, per user reports on Reddit and HN.
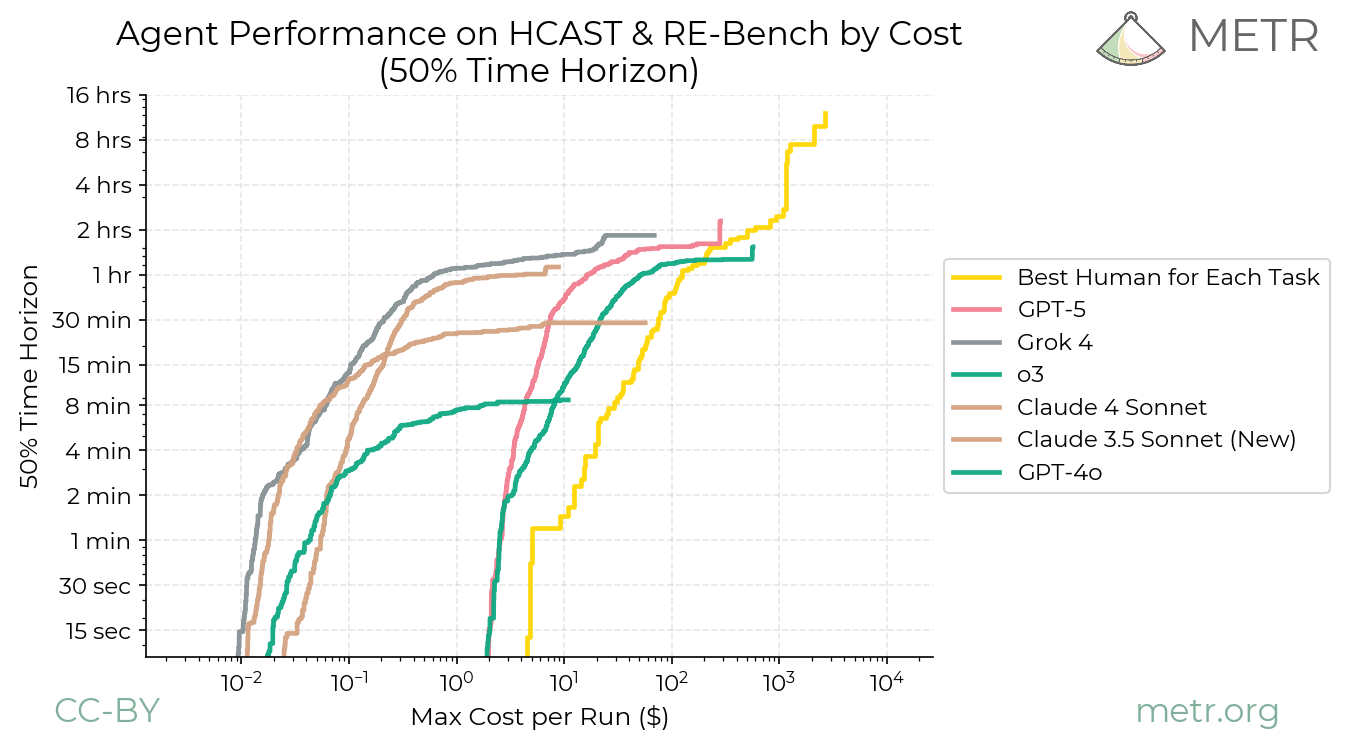
Why? Agents don’t stop at one pass. They plan, act, observe, critique—each step a new API call. A stock trading agent might query markets (1k tokens), analyze charts via vision models (5k), simulate trades (10k), then iterate on feedback. At scale, enterprises deploying 1,000 agents hit $10M+ yearly inference tabs. AWS Bedrock logs show agent workloads spiking 5-10x over chatbots. This isn’t hype; it’s math. If base inference halves yearly (as it has, from $20/M in 2023), agent orchestration offsets gains unless architectures slim down.
2025 Outlook: Constraints Ahead
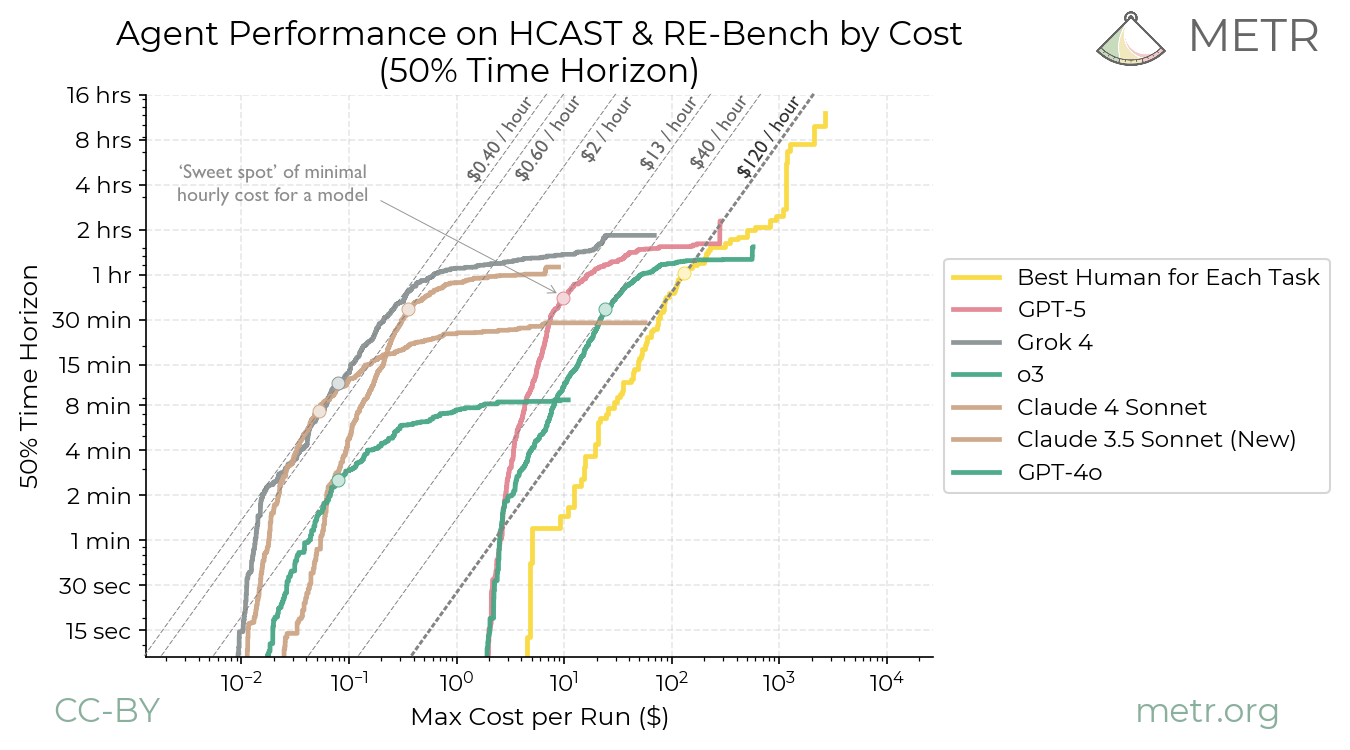
By 2025, expect agent costs to stabilize or dip for narrow tasks but balloon for general autonomy. NVIDIA’s Blackwell B200 GPUs promise 4x inference throughput at similar power, potentially halving cloud rates to $20-30/hour per 8-GPU node. Open-source shifts help: Llama 3.1 405B runs locally on 8 H100s for pennies after quantization. But proprietary agents from OpenAI or Google DeepMind lock users into high-margin APIs.
This matters because viable AI agents reshape labor markets—software engineers, analysts, traders—but only if costs drop below human wages. At $50/hour equivalent today (vs. $100k/year dev salary), they’re niche. Exponential fears stem from unchecked scaling laws, but reality bites: energy caps loom. Global AI power demand could hit 100GW by 2026 (IEA forecast), rivaling Japan’s grid, jacking electricity to $0.15/kWh. Enterprises pivot to hybrid edge-cloud setups or fine-tuned smaller models like Phi-3 (3.8B params, agent-capable at $0.01/task).
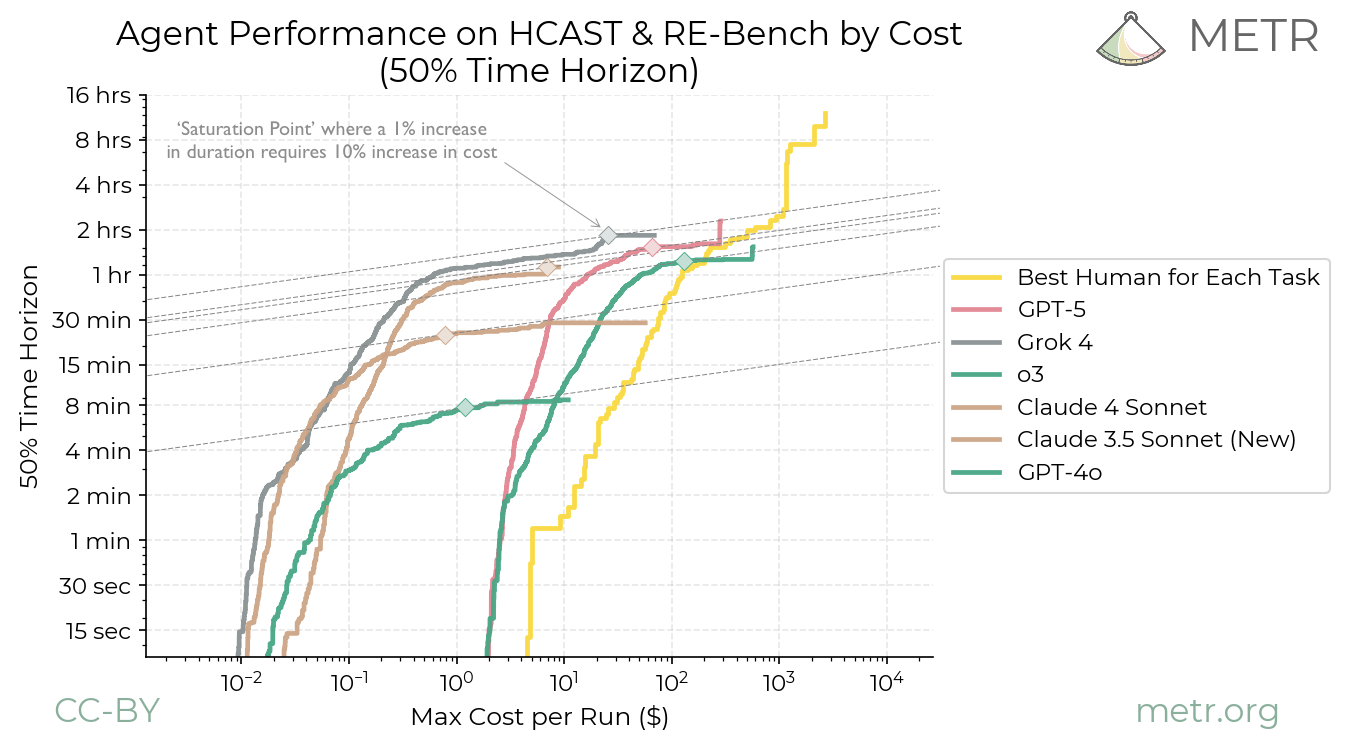
Skeptically, 2025 won’t see agent Armageddon. Costs trend down 30-50% yearly via MoE architectures (Mixture of Experts) routing queries efficiently—Grok-1.5 uses 314B params but activates 25% per token. Why it matters: barriers cull weak players. Startups without infra moats fold; giants like Microsoft (with Azure’s 1M+ GPUs) dominate. Users, audit your agent’s token footprint—tools like LangSmith reveal 80% waste in loops. Trim ruthlessly, or watch budgets evaporate.