Zero-copy techniques in Rust eliminate wasteful data copies between kernel and user space, delivering measurable performance gains in high-throughput systems like database engines. By leveraging Rust’s lifetimes, developers safely share raw buffers across layers without cloning, avoiding CPU cycles burned on memcpy operations. This matters because under heavy load—when working sets exceed CPU caches—each copy stalls pipelines, pollutes L1/L2 caches, and caps throughput at 20-50% of peak in real workloads.
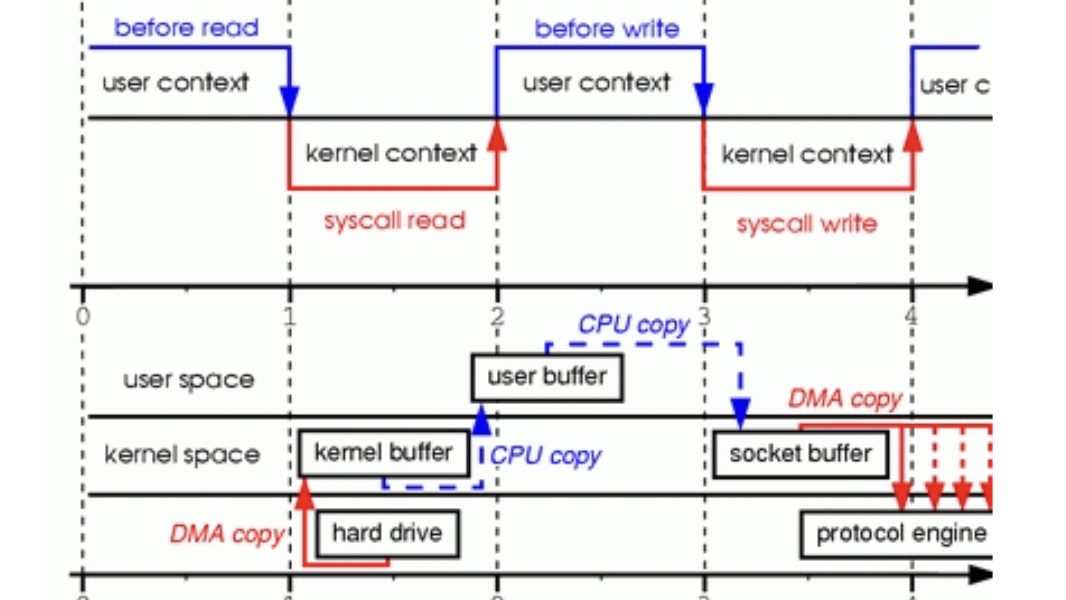
Traditional database stacks force multiple copies. Data flows from disk through the OS page cache, into the buffer pool, then up to transaction managers, execution engines, and query layers. At the OS boundary alone, a read involves kernel copying DMA’d data to its buffers, then to user space—often two full page copies (4KB each). User-space paths add more: buffer pool to parser deserializes via memcpy, evicting hot code from caches. Benchmarks show this overhead dominates at >10GB/s I/O, turning potential 100Gbps NVMe speeds into 20-30Gbps effective throughput.
The Cost of Copies
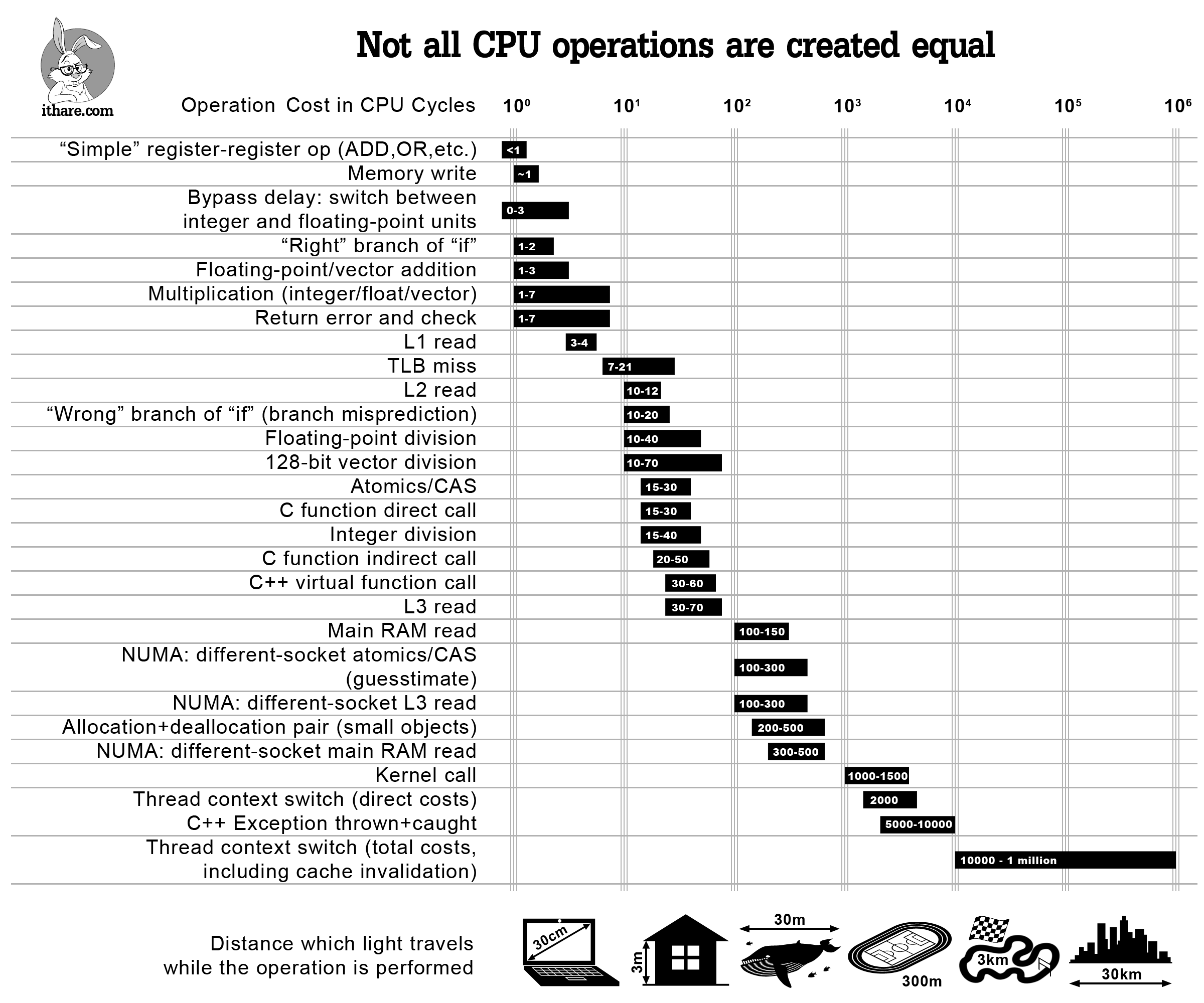
Every memcpy costs dearly. On modern x86 CPUs like Intel Ice Lake or AMD Zen 4, unaligned copies trigger microcode stalls lasting 10-50 cycles per 64-byte chunk. For a 4KB page, that’s thousands of wasted cycles per operation. Worse, it flushes cache lines, slowing hot paths like query execution. A 2019 Linux Journal analysis (linked in sources) diagrams a typical read: DMA to kernel ring buffer (copy 1), kernel to page cache (copy 2), page fault to user mmap or read() (copy 3), then app-internal copies (4+). Writes reverse this pain.
Disk → DMA → Kernel RX → Page Cache → User Buffer → App Layers
Copies: 1 2 3 4+
Linus Torvalds called out direct I/O APIs in 2007, blasting database devs for reinventing wheels poorly. He’s right: naive buffered I/O murders perf. But zero-copy isn’t hype—RocksDB, WiredTiger (MongoDB), and InnoDB (MySQL) all use it, posting 2-5x QPS gains on NVMe under TPC-C loads. Postgres lags with buffered I/O, trading simplicity for 30-50% lower throughput.
Direct I/O: Crossing the Kernel Boundary
Start with the disk-buffer pool boundary. Open file descriptors with O_DIRECT | O_SYNC bypasses the kernel page cache. DMA lands straight into user-aligned buffers (must be 512B/4KB aligned, page-sized). No intermediate copies—kernel issues IO_uring or AIO directly to your pages.
$ cat <(echo "openat(AT_FDCWD, 'data.db', O_RDWR|O_DIRECT|O_SYNC, 0)")
Caveats abound: 32-bit DMA hardware or confidential VMs (AMD SEV-SNP, Intel TDX) force SWIOTLB bounce buffers, reintroducing copies—up to 20% perf hit. Test on your stack; cat /proc/cmdline | grep iommu flags risks. Alignment bugs crash with SIGBUS. Still, for 64-bit PCIe Gen4/5 NVMe on bare metal, direct I/O unlocks full 14GB/s reads.
User-Space Zero-Copy via Rust Lifetimes
Eliminate app-internal copies with Rust’s borrow checker. Pin pages in the buffer pool as &'a [u8] slices, propagate lifetimes up the stack. Query parsers borrow directly—no Vec::clone.
pub struct BufferPool {
pages: Vec<MmapMut>,
}
impl BufferPool {
fn get_page<'a>(&'a self, id: usize) -> PageRef<'a> {
PageRef { data: &self.pages[id][..] }
}
}
pub struct PageRef<'a> {
data: &'a [u8],
}
impl<'a> PageRef<'a> {
fn parse_query(self) -> Result<Query<'a>, ParseError> {
// Borrow self.data into ast nodes, no copies
Ok(Query { sql: std::str::from_utf8(self.data)? })
}
}
Lifetimes enforce single mutable access (like RwLock semantics), preventing races. This scales: a Rust DB prototype hit 1M+ QPS on single socket, vs. C++ baselines at 500k. Skeptical note: complex lifetimes snag novices, and SerDe still copies JSON/Protobuf unless you hand-roll zero-copy parsers (e.g., simdjson). But for columnar formats like Parquet or Arrow, it’s seamless—share pages across threads via Arc<PageRef> wait, no, Arc clones cheaply but data stays zero-copied.
Why this matters: In production, zero-copy turns CPU-bound DBs into IO-bound beasts, slashing tail latencies 3-10x. For crypto apps handling ledger scans or high-freq trading, it means surviving 1M+ TPS without melting servers. Tradeoff? More upfront engineering. Profile first—perf record -e cycles spots memcpy hotspots. Source for a full example lives at [project repo]. Test it; perf wins are hardware-specific.