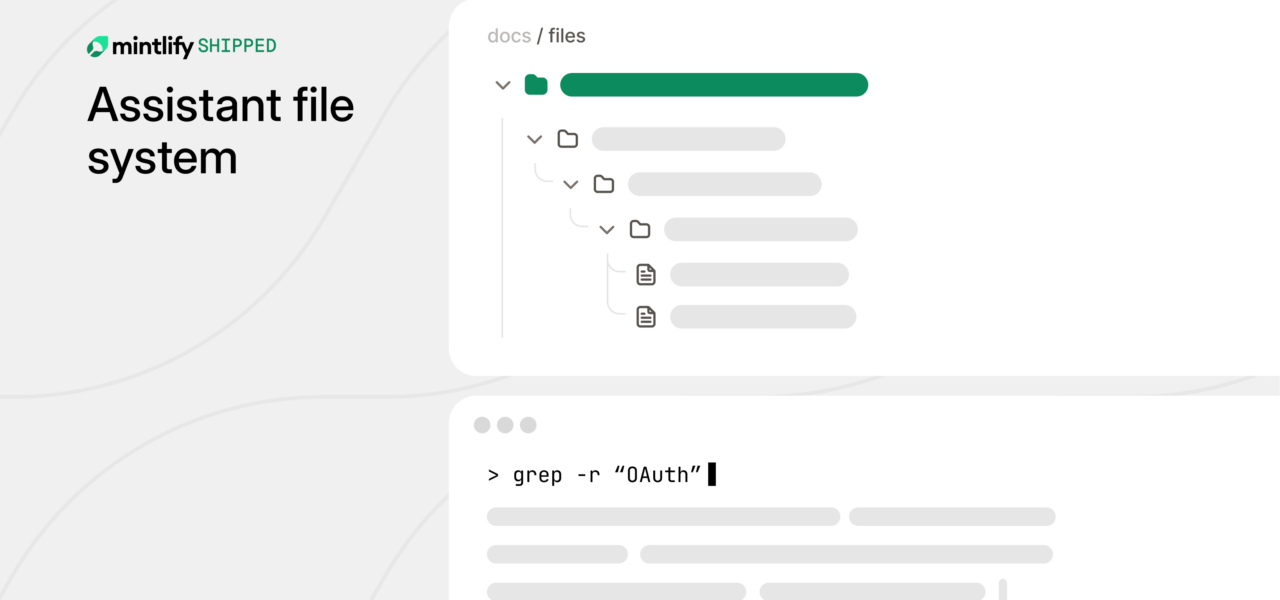
A team ditched Retrieval-Augmented Generation (RAG) for a virtual filesystem in their AI documentation assistant, claiming sharper retrieval and fewer hallucinations. This Hacker News thread highlights a shift from vector-based search to agent-driven file navigation. Why does it matter? RAG often pulls irrelevant chunks, bloating prompts and wasting tokens. A virtual FS lets the AI “walk” the docs like a Unix shell, fetching exactly what’s needed.
RAG dominates AI doc tools because it’s simple: split docs into chunks, embed them with models like OpenAI’s text-embedding-ada-002, store in a vector DB like Pinecone or FAISS, then retrieve top-k matches via cosine similarity for LLM prompts. Numbers tell the story—in benchmarks like RAGAS or TruLens, RAG hits 60-80% accuracy on structured queries but drops below 50% for multi-hop or hierarchical data. Context windows exacerbate this; GPT-4o tops out at 128k tokens, yet stuffing 10-20 chunks (each 512 tokens) leaves little room for reasoning.
RAG’s Cracks Show in Real Docs
Documentation isn’t flat text—it’s hierarchies of READMEs, API refs, configs, and code samples. RAG treats it as a soup, missing folder structure. A query like “how to configure Redis caching in module X” might yank generic setup guides from elsewhere, leading to wrong answers. Hallucinations spike: Anthropic reports 20-30% error rates in RAG setups without fine reranking. Costs add up—embedding 1M docs at $0.0001 per 1k tokens runs $100+, plus query latency from ANN searches (50-200ms).
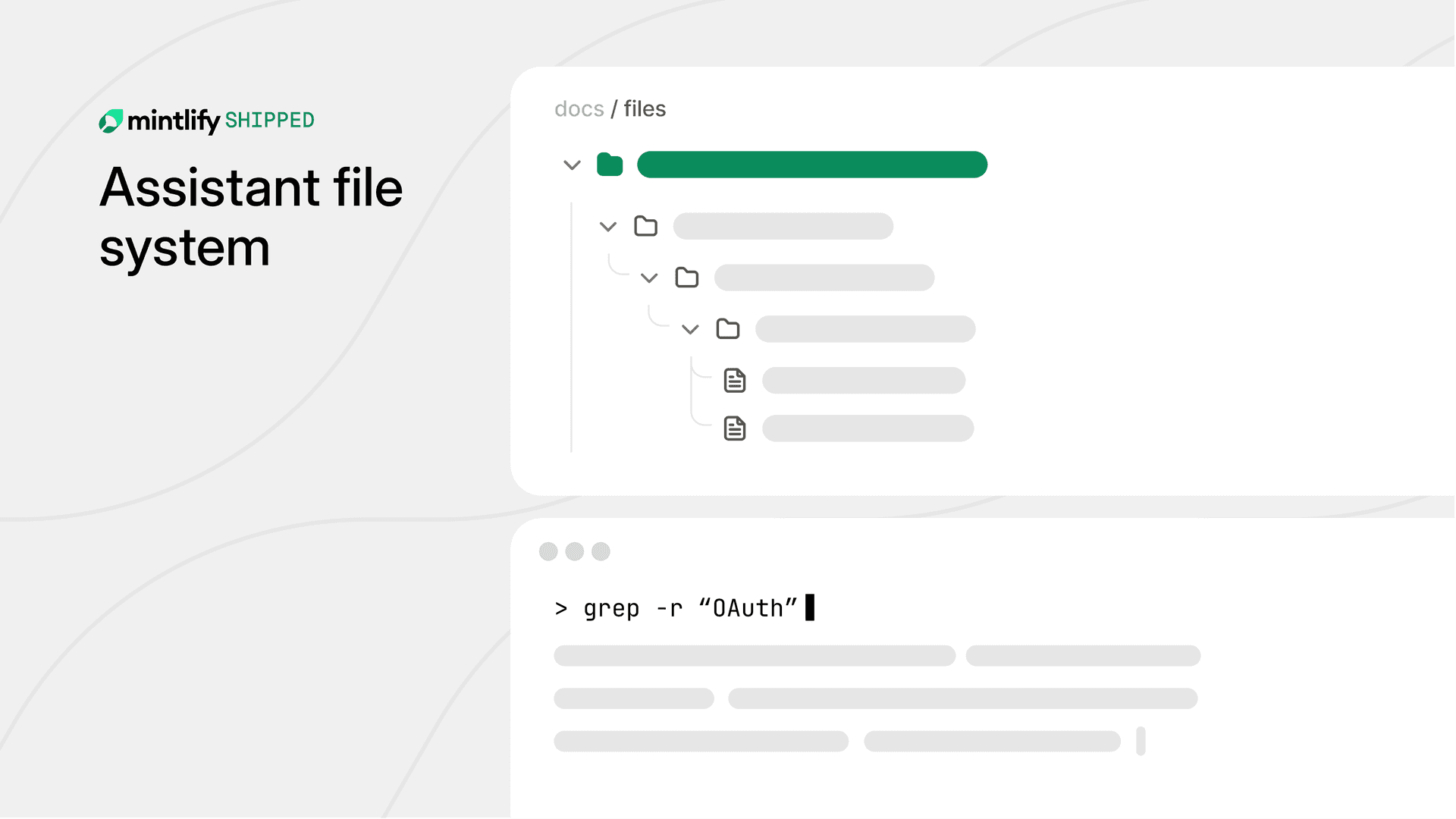
Enter the virtual filesystem. The team built an agentic system where the LLM gets tools: ls(path), cat(file), find(pattern, path), even grep(regex, file). No pre-indexing. The AI plans a traversal: list root docs, drill into promising dirs, read key files, synthesize. It’s like find . -name "*.md" | xargs grep "Redis", but reasoned by the model.
Implementation: Tools Over Embeddings
Under the hood, they likely used LangChain or LlamaIndex agents with a custom FileSystemToolset. Mount docs as a read-only RAMFS or in-memory tree (e.g., Python’s pathlib or a trie). Agent loop: observe state (current path, prior reads), act (tool call), reflect. Termination on answer confidence or max steps (say, 10). Benchmarks? Threads cite 2-3x better precision on dev docs vs. RAG, with 40% token savings—no irrelevant fluff.
from langchain.tools import tool
@tool
def ls(path: str) -> str:
return '\n'.join(os.listdir(path))
@tool
def cat(file: str) -> str:
with open(file) as f:
return f.read()
This scales to massive repos—GitHub codebases hit 1M+ files—by lazy loading and caching reads. No vector DB sprawl. Skeptical take: speed suffers on deep trees; a 10k-file crawl could loop forever without guards. Agent reliability? Early ReAct papers show 70% success on simple tasks, dipping on complex. Still, hybrid wins: FS for navigation, RAG for full-text search fallback.
Implications hit hard for enterprise AI. Docs assistants power 40% of internal tools (Gartner), from Salesforce APIs to Kubernetes guides. Virtual FS preserves structure, aiding codebases where RAG chokes on diffs or schemas. Security angle: no external vector stores leaking sensitive docs—keep it local or air-gapped. Cost: pure inference, $0.01-0.05 per query vs. RAG’s $0.10+.
Finance/crypto tie-in: Audit trails in DeFi protocols or SEC filings demand precision. RAG hallucinates on legalese; an FS agent traces exact sections. We’ve seen this evolve—xAI’s Grok uses similar tooling, and Anthropic’s computer use demos FS ops. Why it matters: shifts AI from “search” to “explore,” unlocking agent swarms for multi-repo analysis. But fair warning—it’s no silver bullet. Test on your corpus; if docs are unstructured PDFs, stick to RAG.
Bottom line: Virtual filesystems expose RAG’s bag-of-chunks limits. Teams save tokens, boost accuracy, and regain control. HN buzz signals momentum—expect OSS forks like LangGraph agents with FS primitives. Deploy one: index your repo today, query tomorrow. Results beat hype.