MariaDB servers at Frappe Cloud froze weekly—5 to 6 incidents across shared and dedicated setups—affecting thousands of hosted sites. Each freeze followed sudden disk I/O spikes, not gradual resource exhaustion. Simple scaling wouldn’t fix it. The team traced the root cause using eBPF kernel probes, revealing a rogue query hammering tables without indexes. This matters because poor query design can crash entire hosting clusters, and traditional monitoring fails under load.
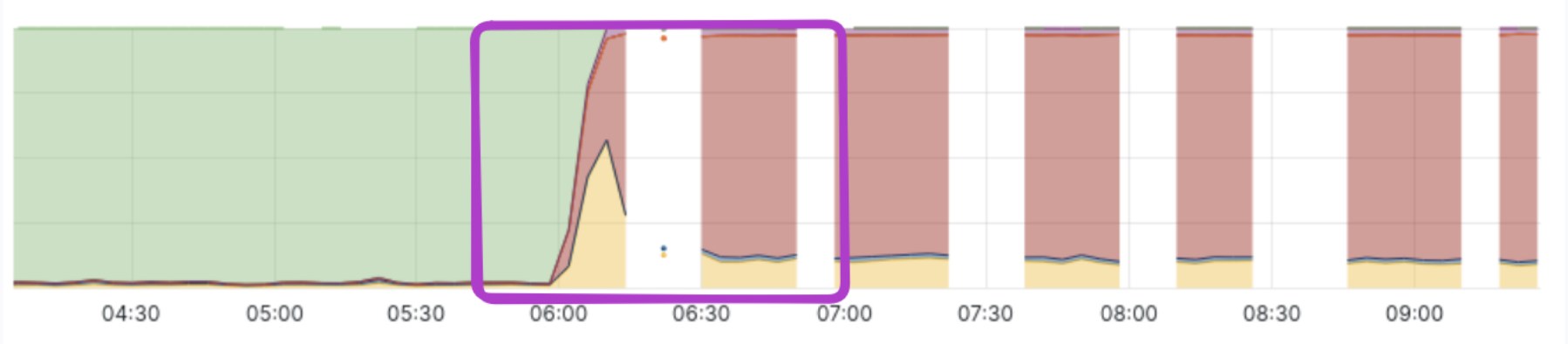
Over recent quarters, Frappe reduced most incidents sharply. Database freezes persisted. Metrics showed disks maxing out, queues ballooning, servers unresponsive. SSH failed. Even monitoring exporters timed out. Visibility vanished exactly when needed. No logs captured running queries or I/O targets during peaks.
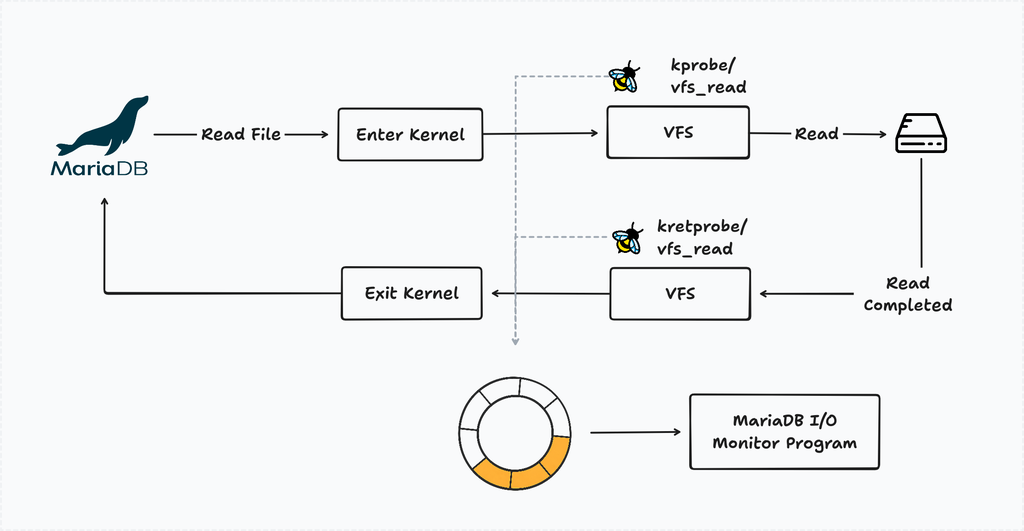
Process lists from MariaDB pinned active queries easily. Pinpointing I/O culprits required kernel-level tracing. Enter eBPF: Linux’s eBPF attaches tiny programs to kernel events without recompiling or rebooting. Frappe hooked kprobe/vfs_read, kprobe/vfs_write for entry, and kretprobe/vfs_read, kretprobe/vfs_write for exit—flagging stalls when reads/writes hung.
They paired entry/exit per file descriptor. Stalled I/O? Log the process, PID, file. To avoid constant overhead, a watchdog monitored CPU iowait and disk utilization. Spikes triggered probes dynamically. Overhead stayed low: eBPF maps buffered events efficiently, processed userspace-side.
Root Cause: Indexless Table Scans
Traces from multiple incidents converged on one pattern. MariaDB’s InnoDB scanned entire tables—gigabytes of data—for queries lacking indexes or LIMIT clauses. A common offender in ERPNext setups (Frappe’s stack): ad-hoc reports or audits pulling from tabDocEvents or communication logs without filters. One trace showed a SELECT on a 50GB table, reading 10M+ rows sequentially.
Why the spike? InnoDB buffers pages in memory but flushes dirty ones during checkpoints. Under query load, random reads evicted clean pages, forcing disk fetches. Doublewrite buffer amplified writes. I/O queue hit 1000+, latency spiked to seconds per op. System ground to halt.
Skeptical note: eBPF shines here, but it’s no silver bullet. Probe bloat risks instability; Frappe’s on-demand activation smartly limits it. Still, kernel panics from bad eBPF aren’t mythical—test rigorously.
Fixes and Implications
They added indexes on frequent scan columns. Query analyzers flagged indexless plans preemptively. Rate-limited long-running queries via MariaDB’s max_execution_time. Incidents dropped to near-zero post-deploy.
This exposes hosting pitfalls. Shared DBs amplify bad tenants—one site’s sloppy query DoS’s all. Dedicates aren’t immune if self-serve. Implications for operators: invest in load-aware observability. Prometheus/Node Exporter fails at crunch time; eBPF or flame graphs deliver truth.
For users: audit queries. Full scans on production tables? Recipe for outage. Use EXPLAIN, add indexes, paginate. In MariaDB 10.6+, performance_schema tracks I/O per query—pair with slowlog.
Code example for their eBPF watcher (adapted):
# Resource monitor script (pseudocode)
while true; do
iowait=$(cat /proc/stat | awk '/iowait/ {print $5}')
util=$(iostat -d 1 1 | tail -1 | awk '{print $NF}')
if (( iowait > 20 || util > 90 )); then
bpftrace -e 'tracefile.bt' # Attach probes
fi
sleep 5
done
Bottom line: eBPF democratizes kernel debugging. Frappe’s 5-6 weekly fires now embers. Your stack next? Probe it before it probes you.