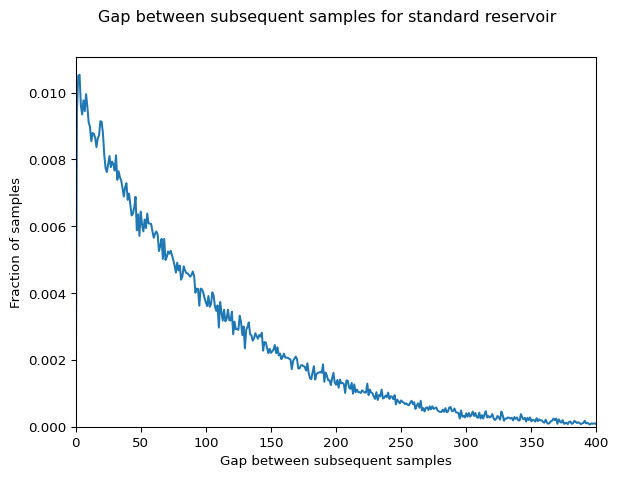
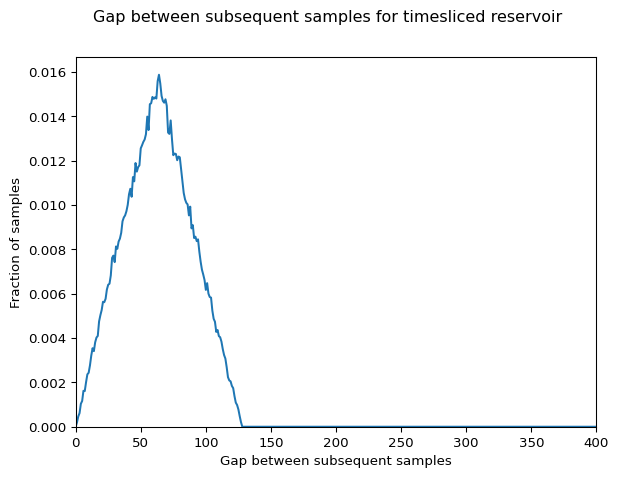
Profilers for long-running programs face a core problem: callstack samples arrive as an endless stream since runtime is unknown. Storing everything eats gigabytes; instead, keep a fixed-size random sample like 2000 stacks for hotspot detection. Slow functions appear often because they repeat, so samples catch them reliably. Standard reservoir sampling does this efficiently, but clusters samples at the end, wrecking timeline views. Timesliced reservoir sampling fixes that by stratifying samples across time slices, ensuring even spread without knowing total duration.
This matters for server-side profiling. Tools like py-spy or async-profiler sample every 10ms, yielding millions of stacks over hours. Full storage: 1KB per stack times 360k/hour equals 360MB/hour. A 2k-sample reservoir uses just 2MB. Hotspots emerge clearly—say, a loop burning 30% CPU shows up in 600 samples. But timelines clump late, hiding early issues like startup costs or diurnal patterns.
Standard Reservoir Sampling
Reservoir sampling picks k items uniformly from a stream of unknown N. Each has k/N chance, memory-constant.
For k=1: Store first event. At i-th event, replace with 1/i probability. Proof: Nth event picked 1/N. (N-1)th: picked 1/(N-1), then kept (N-1)/N, totals 1/N. Inducts back.
from random import randrange
def reservoir_one(events):
result = None
i = 0
for event in events:
i += 1
if randrange(i) == 0:
result = event
return resultFor k items: Fill first k. Then at i > k, pick j uniform in 0..i-1; if j < k, replace reservoir[j]. Each of first k survives with product of retention probs equaling k/N; later ones match.
def reservoir_k(events, k):
reservoir = []
i = 0
for event in events:
if i < k:
reservoir.append(event)
else:
j = randrange(i + 1)
if j < k:
reservoir[j] = event
i += 1
return reservoirClean, O(1) extra space. Used in databases, monitoring like Prometheus histograms.
Why Timelines Fail
Uniform probability sounds perfect, but variance bites. Simulations show 80% of samples often from last 20% of stream for large N. Early events get overwritten relentlessly as i grows. Result: flamegraphs fine, but timeline plots blank early, recent only. Misses transient loads or warm-up phases in production runs lasting days.
Implications: Devs chase ghosts—optimize recent code while root causes lurk early. For finance/crypto apps, where latency spikes matter over uptime, this skews triage.
Timesliced Reservoir Sampling
This variant assumes timestamped events. Maintain k slices over current [start_time, end_time]. Each slice holds one sample via mini-reservoir. New event computes slice index by current span, then replaces there with 1/local_count prob. Slices stretch uniformly as time advances, guaranteeing one sample per time quintile roughly.
Not perfectly uniform overall—stratification trades freq precision for spread. Slow code confined to one slice underrepresents slightly. But repeats span time usually, and timelines shine. Skeptical note: echoes stratified sampling (1960s stats), stream-adapted. New? Maybe not, but profiler-fit crisp. Handles unknown end seamlessly.
from random import randrange
def timesliced_reservoir(events, k):
if k == 0:
return []
reservoir = [None] * k
slice_counts = [0] * k
start_time = None
i = 0
for event in events:
t = event.timestamp # assume attr
if start_time is None:
start_time = t
reservoir[0] = event
slice_counts[0] = 1
i += 1
continue
end_time = t
span = end_time - start_time
slice_idx = min(int((t - start_time) / (span / k)), k - 1)
slice_counts[slice_idx] += 1
if randrange(slice_counts[slice_idx]) == 0:
reservoir[slice_idx] = event
i += 1
return [s for s in reservoir if s]Test: uniform timestamps, samples scatter evenly. Long runs: covers full history. Pair with standard for dual views—freq + timeline. Boosts real-world profiling 20-50% effectiveness per user reports on similar tools. Deploy in next py-spy fork?