A developer launched a simple download server for 2.2GB digital files on a Hetzner box with just 40GB disk and 4GB RAM running NixOS. Minutes after announcing availability, hundreds of customers hit the site. Disk filled to 100% instantly. Email deliveries failed with “452 4.3.1 Insufficient system storage.” Users couldn’t download files. Grafana and df -h confirmed /dev/sda at capacity. This exposed classic production pitfalls: analytics bloat, Nix store explosion, and overlooked log growth under load.
The Barebones Setup
The server ran a Haskell program serving static files behind authorization checks, fronted by nginx as a reverse proxy for a virtual host. Hetzner’s CX11 plan—€3.29/month—delivers that spec: single-core AMD EPYC, 40GB NVMe SSD. Fine for low-traffic prototypes, but tight for bursts. NixOS managed the stack declaratively, including Plausible Analytics for privacy-focused tracking. Plausible relies on ClickHouse, a columnar database that chews disk on queries and logs.
No cloud storage for the 2.2GB files. Everything sat local. Smart for control and cost, but risky. One file equals 5.5% of total disk. Hundreds downloading simultaneously? Cache misses and temp files pile up fast.
Traffic Spike Triggers Cascade
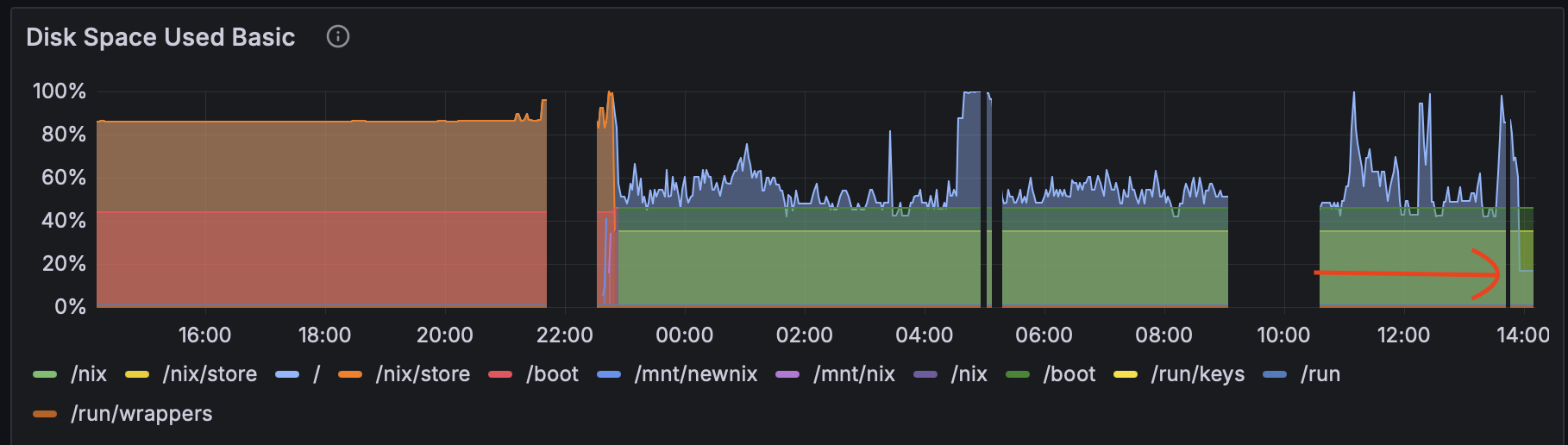
Logs flooded: Mar 31 20:43:03 mogbit kanjideck-fulfillment[2528300]: user error (Unexpected reply to: MAIL "...@kanjideck.com", Expected reply code: 250, Got this instead: 452 "4.3.1 Insufficient system storage"). SMTP rejected outbound mail. Incoming complaints likely dropped too. Disk at 40GB/40GB.
du -sh scans revealed culprits: /var/lib Plausible’s ClickHouse database at 8.5GB, /nix/store at 15GB with generations of configs and binaries. That leaves ~16GB unaccounted—author later realized “rest of files” couldn’t explain it. Likely suspects: journald logs exploding from request volume, nginx access logs, Haskell temp files, or ClickHouse write-ahead logs.
Panic mode. First fix attempt:
nix-collect-garbage -d to nuke old profiles and store. Failed: error: opening lock file '/nix/var/nix/profiles/system.lock': No space left on device. Nix needs breathing room to run GC—ironic for a reproducibility tool.
Desperate Space Hunt
Quick win:
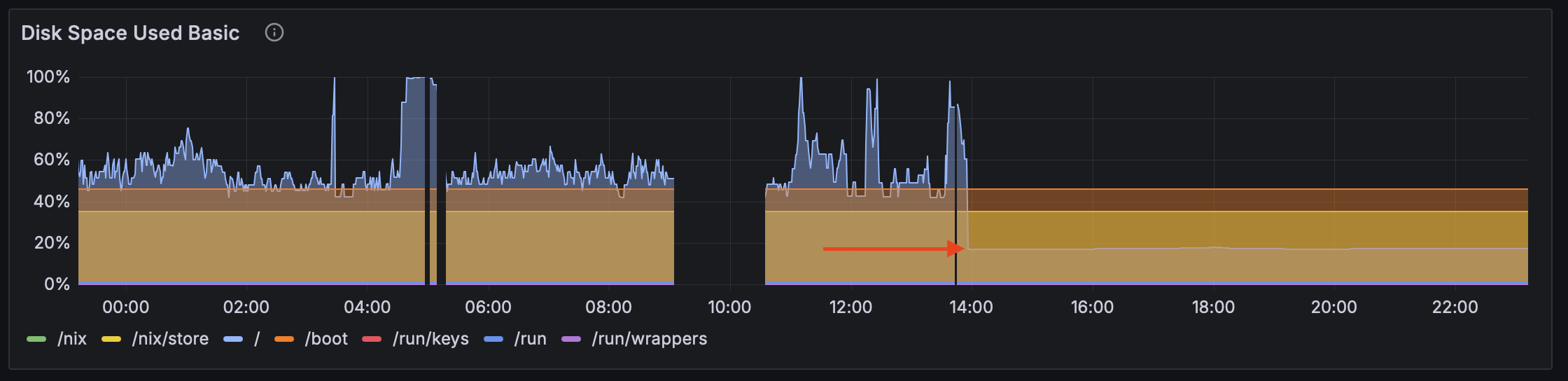
journalctl --vacuum-time=1s. systemd’s journal freed enough for Nix GC to proceed, reclaiming 15GB. Next: Shrink ClickHouse. Plausible logs every query to system.query_log. Attempt:
clickhouse-client -q "TRUNCATE TABLE system.query_log"Failed: Code: 243. DB::Exception: Cannot reserve 1.00 MiB, not enough space. ClickHouse buffers aggressively; even TRUNCATE needs temp space.
Real fix likely involved stopping services, rm -rf large dirs, or clickhouse-client --query="SYSTEM DROP REPLICA ..." on logs. Restart analytics, or offload to external. For files, migrate to S3-compatible like Hetzner Storage Box (€3/month for 100GB) or Backblaze B2 (pennies per GB).
Why This Bites—and How to Avoid
Small instances tempt startups: low cost, quick spin-up. But 40GB caps real-world use at ~20GB safe headroom after OS/Nix overhead. Plausible’s ClickHouse grows 1-5GB/month on modest traffic; spikes multiply it. Nix/store hits 10-20GB easy with iterations. Add logs: game over.
Implications hit hard for indie devs. Downtime erodes trust—KanjiDeck customers waited months for files, then 503s. Revenue risk if paid. Scale math: 100 users x 2.2GB = 220GB theoretical transfer; reality needs bandwidth too (Hetzner CX11 caps 20TB/month outbound).
Fixes: Alert on 80% disk via Prometheus/Grafana (they had Grafana—use it). Separate concerns: static files to CDN/object store. Run analytics on beefier box or hosted (Plausible Cloud starts €5/month). NixOS trick: nix.gc.keep-derivations=false in config, auto-GC more aggressively. Or ditch Nix for Docker if purity isn’t critical.
Skeptical take: Tools like NixOS and Plausible prioritize ideals—reproducibility, privacy—over pragmatism. Great for side projects; production demands ruthless optimization. Monitor everything. Size disks for peaks, not averages. One launch-day disk OOM, and your MVP is DOA.