Trip Venturella just dropped Mr. Chatterbox, a 340 million parameter language model trained from scratch on 28,035 books from the British Library’s Victorian-era collection. Every token—2.93 billion after filtering—comes from texts published between 1837 and 1899. No modern data, no scraped web slop, no copyright headaches. The model weighs 2.05 GB and runs on your local machine.
This matters because most LLMs guzzle unlicensed internet data, sparking lawsuits like The New York Times’ suit against OpenAI or Getty’s against Stability AI. Mr. Chatterbox sidesteps that entirely. Public domain texts from institutions like the British Library offer a clean path forward. Venturella used Andrej Karpathy’s nanoGPT framework to train it, proving small-scale ethical training is feasible on consumer hardware.
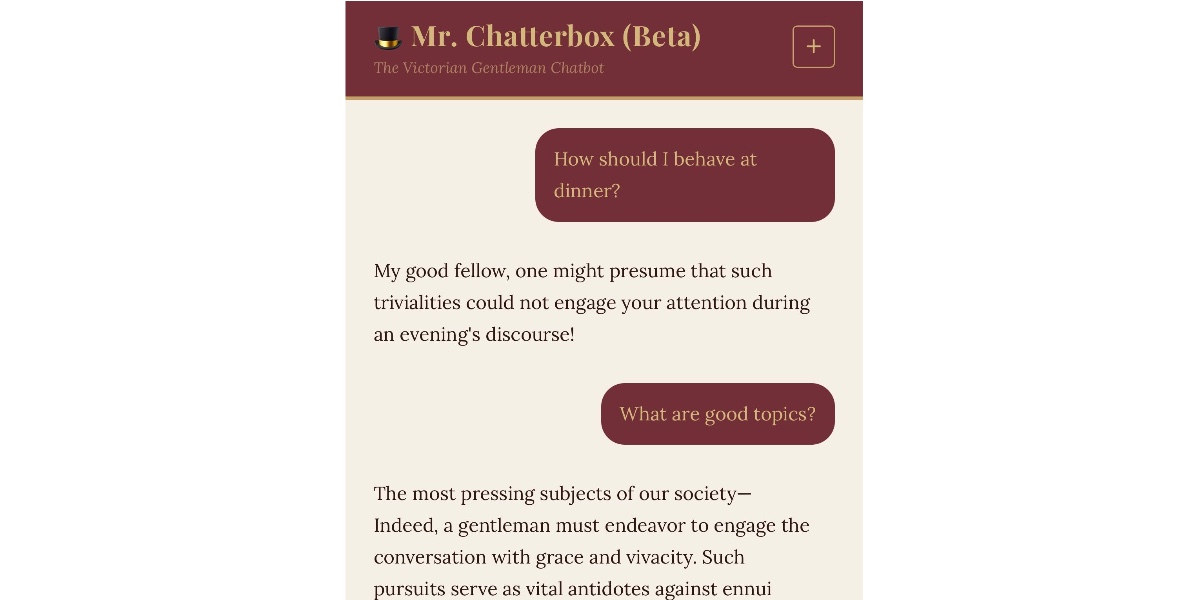
Performance: Victorian Charm, Modern Weakness
Expect disappointment if you want coherent answers. Simon Willison tested it via Hugging Face and called it “pretty terrible”—more Markov chain than LLM. Responses drip with 19th-century diction: flowery, archaic, occasionally nonsensical. Ask about today’s news? It hallucinates in period costume.
Chinchilla scaling laws explain why. The 2022 DeepMind paper recommends 20 tokens per parameter. For 340M params, that’s 6.8 billion tokens—over twice what Chatterbox got. Modern models like Qwen 2.5’s 0.5B version shine at 2B params with far more data. Scale this project up with better public domain corpora, and you might get something useful. Right now, it’s a curiosity.
Why care? It baselines what pure historical data yields. No post-1899 knowledge means zero awareness of 20th-century events, tech, or science. Vocabulary tops out at “phrenology” and “ether.” Fun for roleplay, useless for facts.
Run It Yourself: Local Control, No Phoning Home
Privacy-focused users take note: this model downloads once and runs offline. No API keys, no cloud telemetry. Willison built an LLM plugin for his llm tool. Install with:
llm install llm-mrchatterboxFirst prompt pulls the weights:
llm -m mrchatterbox "Good day, sir."Or chat persistently:
llm chat -m mrchatterboxIt leverages nanoGPT’s inference code, tweaked for compatibility. On an M1 Mac, it generates at 10-20 tokens/second. CPU-only setups work too, just slower. Full code is on GitHub under llm-mrchatterbox.
Implications: A Blueprint for Ethical, Private AI
Big AI trains on trillions of tokens, much contested. Public domain alternatives exist: Project Gutenberg (70k books), HathiTrust (17M volumes, many free post-1928). Combine with Wikisource or Europeana, and you hit billions ethically. Tools like Datasette let you query these datasets directly.
Security angle: Local models like this dodge data exfiltration risks. In crypto or finance ops, where leaks cost millions, self-hosted LLMs prevent vendor lock-in and surveillance. Pair with Ollama or llama.cpp for quantization, and it sips RAM.
Skeptical take: 340M params is toy size. GPT-2’s 345M version needed diverse modern data to work. Victorian lit is narrow—mostly British novels, pamphlets, sermons. Bias toward empire-era views on class, gender, empire. Still, Venturella’s experiment spotlights scalable ethics. Double the data, hit Chinchilla ratios, and watch it evolve. For now, download it, prompt “What ho, varlet?”, and enjoy the anachronistic banter.






