Open-source AI models saw unusual diversity this March 2026, with releases spanning speech recognition, multilingual LLMs, and efficient MoE architectures from NVIDIA, Cohere, Sarvam, and Mistral. Unlike typical rounds dominated by massive Chinese LLMs like Qwen or DeepSeek, this batch includes specialized tools for OCR, RAG retrieval, audio transcription, code editing, and math proving. New players from India and relaxed licenses signal a maturing ecosystem that prioritizes practical, domain-specific tools over headline-grabbing scale.
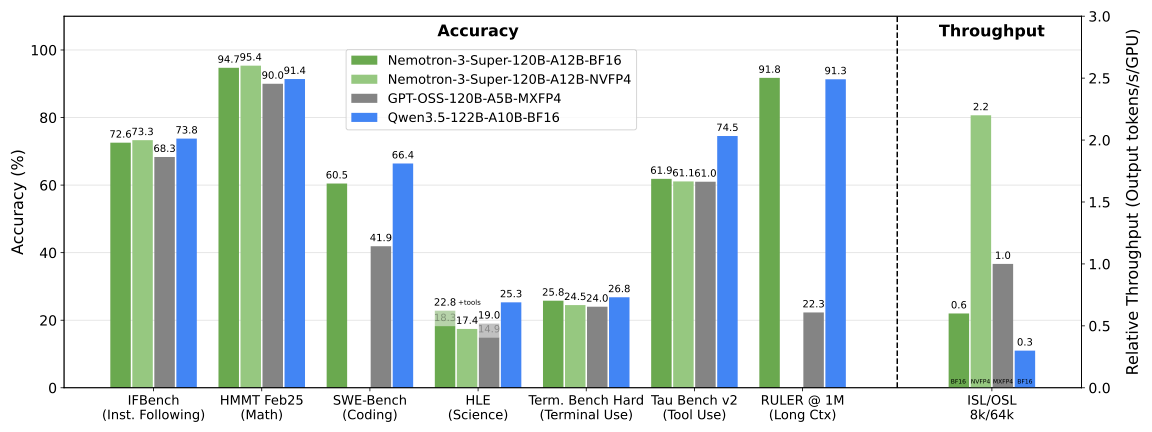
NVIDIA leads with Nemotron-3-Super-120B-A12B-NVFP4, a 120 billion parameter model activating just 12 billion at inference via LatentMoE. It handles 1 million token contexts and supports languages like English, Spanish, French, German, Hindi, and Arabic. NVIDIA pretrained it using NVFP4 quantization—a first for open models—reducing memory needs without quality loss. They released a detailed tech report, pre-training data (mostly open), and post-training datasets. Benchmarks show it competes with denser 70B models on reasoning tasks while using 70% less VRAM. This matters because MoE sparsity cuts inference costs dramatically; at scale, it could slash API bills from $0.50 to $0.15 per million tokens on H100s.
Specialized Models Break New Ground
Cohere’s Transcribe-03-2026 shifts their focus to audio. Built on conformer architecture like NVIDIA’s Parakeet, it transcribes 14 languages including Arabic, Hebrew, and Hindi. Cohere claims word error rates 15-20% below open rivals like Whisper-medium and closed options like Google Cloud Speech. Released under Apache 2.0—unlike their prior non-commercial licenses—it invites commercial deployment. Developers can fine-tune it for accents or jargon, enabling cheap, private transcription servers. In a world of $0.006/minute cloud APIs, self-hosting this cuts costs 80% and dodges data leaks.
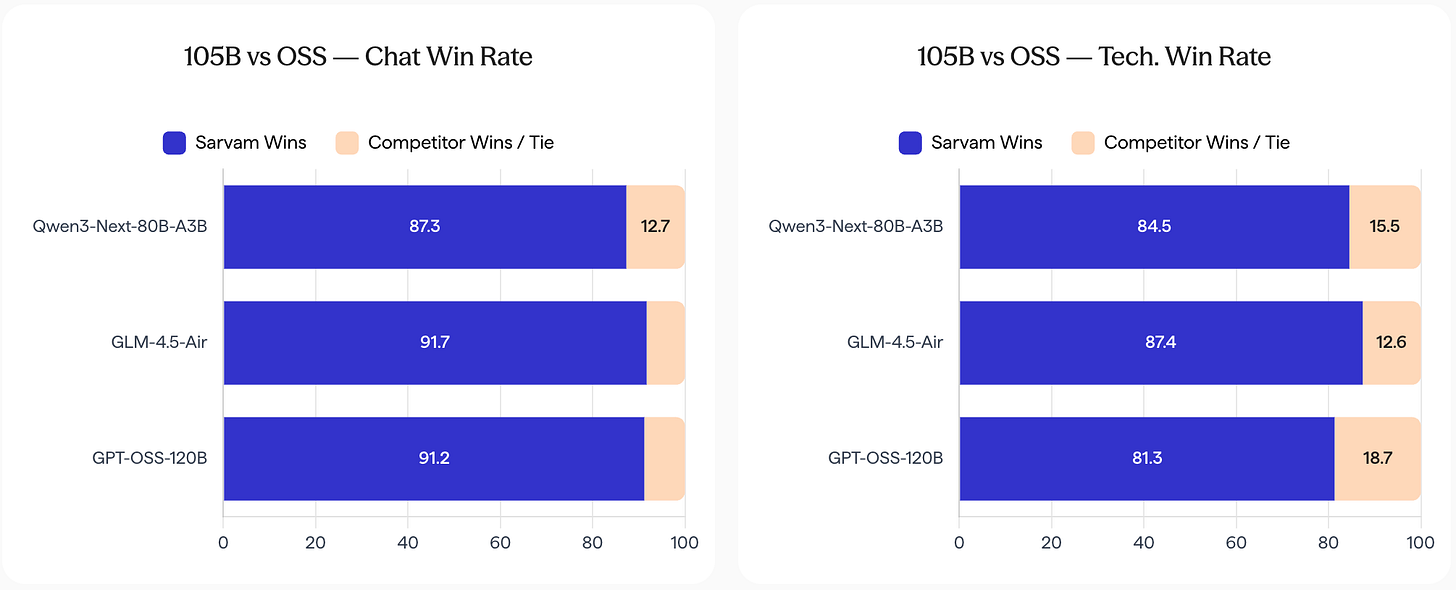
Sarvam AI, an Indian startup, dropped sarvam-105B (105B total, 10B active) and a 30B-A2B variant, trained on 12-16 trillion tokens heavy in Indic languages. They outperform Llama-3.1-70B and Qwen2.5-72B on Hindi, Tamil, and Bengali benchmarks by 10-25% preference scores. This underscores sovereign AI: Western models hallucinate or bias on non-English data, while Sarvam integrates cultural nuance. India, with 1.4 billion people and 22 official languages, needs this; global firms ignore it at their peril. Expect similar pushes from Brazil or Indonesia soon.
Mistral’s Small-4-119B-2603 merges their prior generations into a 119B-A7B MoE. It edges Mixtral-8x22B on MMLU (78.5% vs 77.2%) with half the active params. Mistral open-weights it under their permissive license, fueling agentic workflows. Other notables include OCR models beating Tesseract by 30% on receipts, RAG retrievers topping 85% recall on financial docs, and theorem provers solving 40% more Lean problems than prior opens.
Implications for Builders and Deployers
This diversity counters the “bigger is better” trap. Giant closed models like GPT-5 dominate headlines but cost $100M+ to run at scale. These open artifacts—many under 100B params—deliver 80-90% performance for pennies. NVIDIA’s data release accelerates replication; researchers rebuilt similar MoEs in days. Sarvam proves national compute investments pay off: India’s 10,000-GPU clusters yield models useless elsewhere but vital locally.
Skeptically, claims like Cohere’s require independent evals—vendor benchmarks often cherry-pick. Still, Apache licenses and open data lower barriers. Security pros gain auditable models, dodging proprietary black boxes. Finance teams build RAG on internal filings without vendor lock-in. Why it matters: Open ecosystems fragment monopoly risks. As closed agents commoditize, specialized opens handle edges cheaply, sustaining innovation. Track these on Hugging Face; next month could normalize such breadth.