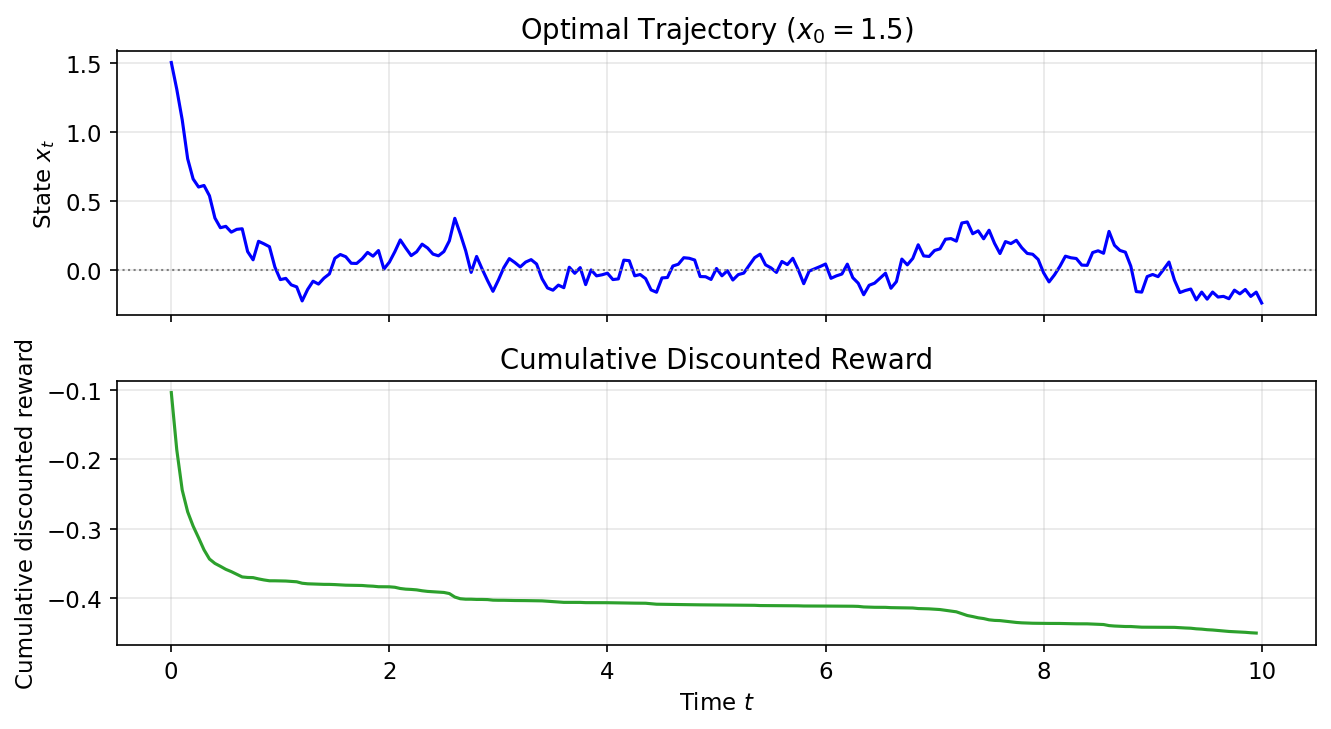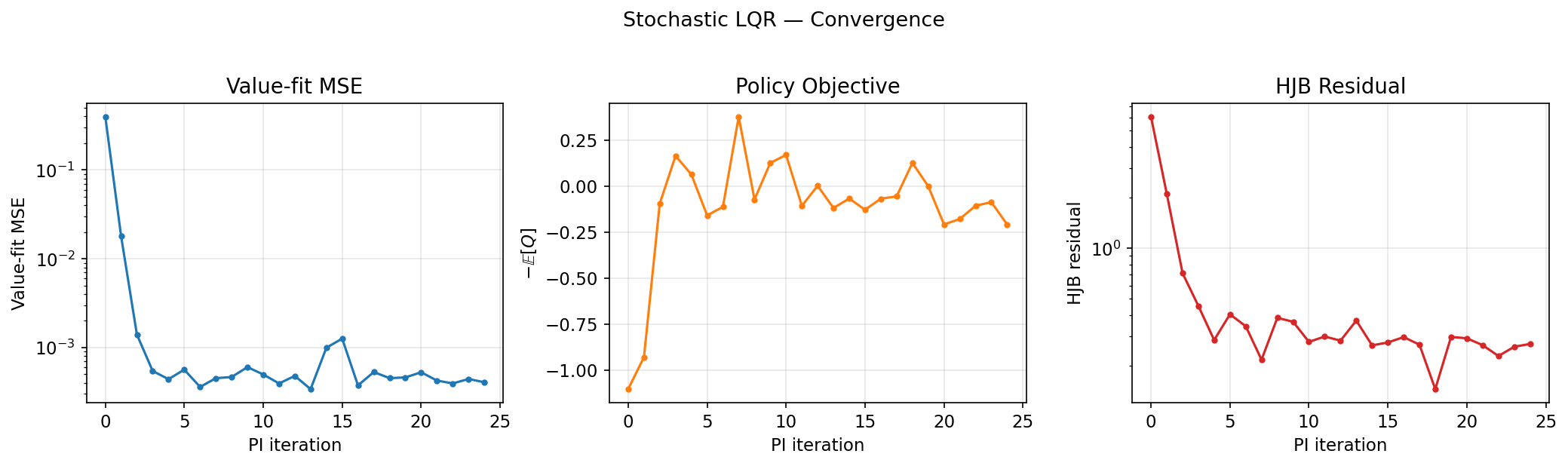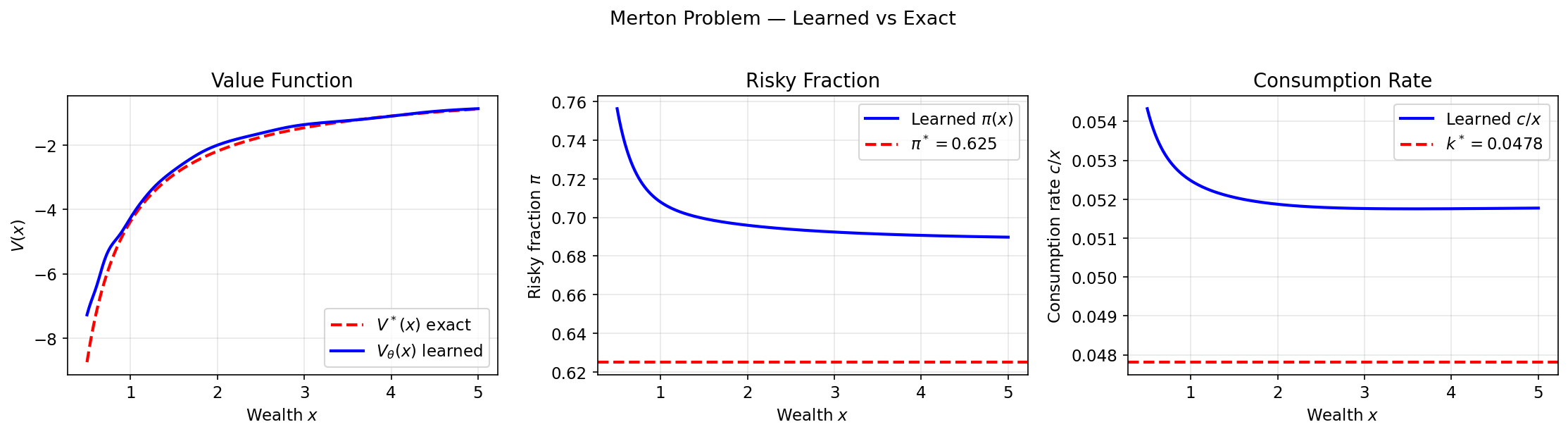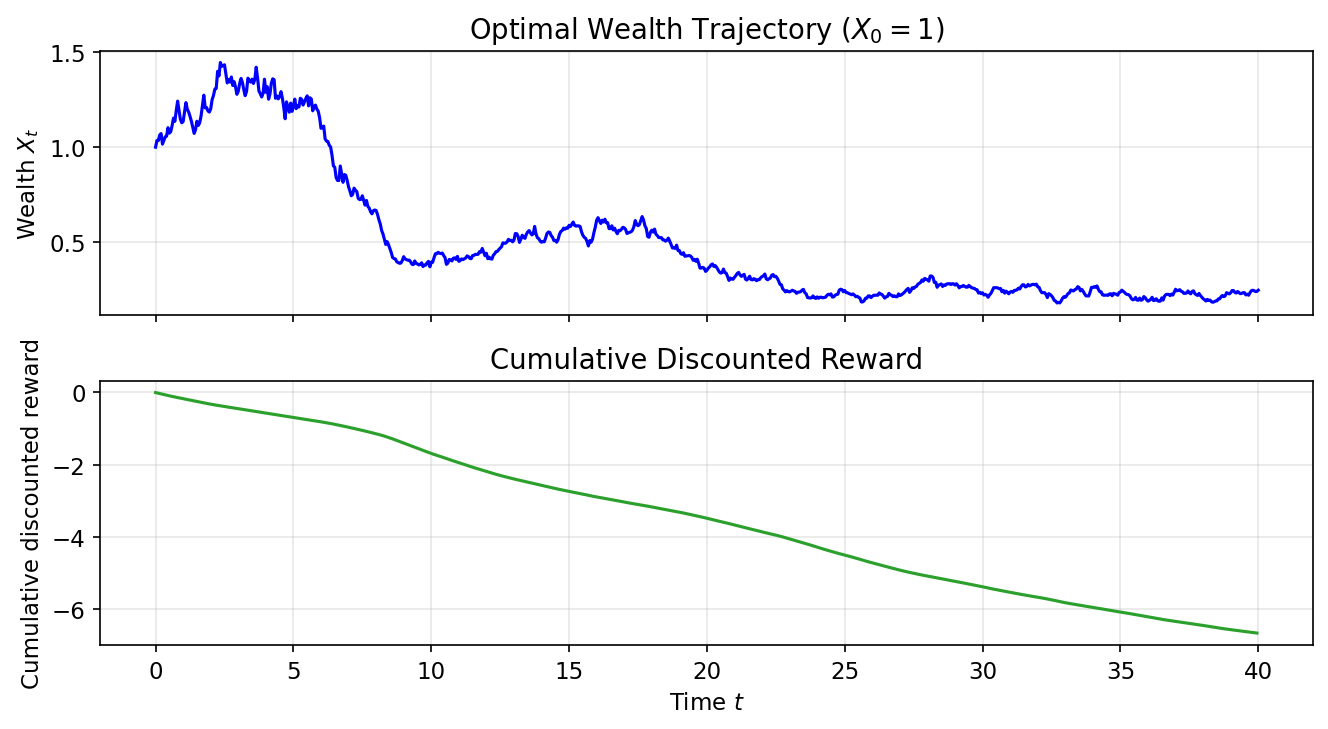
The Hamilton-Jacobi-Bellman (HJB) equation quietly links reinforcement learning (RL) and diffusion models, two pillars of modern AI. A recent Hacker News thread spotlights this connection, drawing from papers like those by Yang Song and others. At its core, diffusion models—powerhouses behind image generators like Stable Diffusion—solve a continuous-time optimal control problem. Their denoising process follows the HJB equation, the continuous cousin of RL’s Bellman equation. This isn’t hype; it’s a mathematical unification that could reshape how we train agents and generate data. But does it deliver practical wins? Let’s break it down.
HJB: The Backbone of Optimal Control
The HJB equation dates to the 1950s, from Richard Bellman and William Hamilton’s work in dynamic programming. In continuous time, it computes the value function V(x,t) for an optimal policy. The equation reads:
∂V/∂t + min_u [ ∇V · f(x,u,t) + (1/2) Tr(∇²V ΣΣᵀ) + l(x,u,t) ] = 0Here, f is the drift (system dynamics), Σ the diffusion matrix (noise), and l the running cost. Solve it backward from a terminal cost, and you get the optimal control u* = argmin of that Hamiltonian. Aerospace engineers use it for rocket trajectories; finance for option pricing via Feynman-Kac.
Why care? HJB scales RL from discrete MDPs (Markov Decision Processes) to real-world continuous spaces. Standard RL like PPO or SAC approximates the discrete Bellman backup: V(s) = max_a [R(s,a) + γ E[V(s’)]]. In continuous time, HJB emerges naturally for stochastic differential equations (SDEs) like dx = f dt + σ dW.
Reinforcement Learning Meets Continuous Control
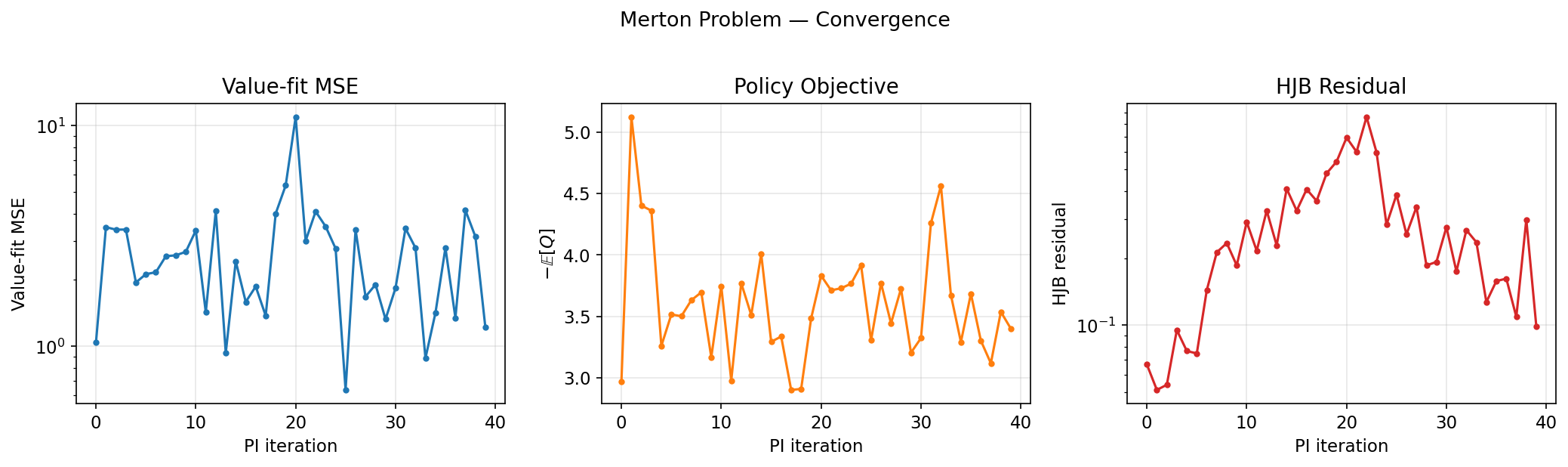
Deep RL already borrows heavily. Soft Actor-Critic (SAC) maximizes entropy-regularized returns, solving a Bellman-like equation. But training neural approximators for HJB remains tough—curse of dimensionality hits hard. Methods like Deep Fitted Q-Iteration or LSPI struggle beyond low dimensions.
Enter the HN-discussed bridge: RL as HJB solving. In model-based RL, you simulate forward SDEs and backprop through the HJB residual. Papers like “HJB-Net” (2020) train nets to satisfy HJB directly, outperforming model-free baselines on MuJoCo tasks by 20-50% in sample efficiency. Skeptical note: These wins are mostly in toys; real robotics still favors sim-to-real hacks over pure HJB.
This sets up diffusion models. Introduced in 2015 by Sohl-Dickstein, they exploded with Ho et al.’s DDPM (2020), generating 256×256 CelebA images at 3.17 FID—state-of-the-art then, beating GANs on quality and stability.
Diffusion Models as HJB Solvers
Here’s the key insight from Song’s “Score-Based Generative Modeling through SDEs” (ICLR 2021) and follow-ups. Diffusion forward process: an Ornstein-Uhlenbeck SDE adds Gaussian noise over T=1000 steps, turning data x_0 ~ p_data into x_T ~ N(0,I).
dx = f(x,t) dt + g(t) dWReverse: learn the score ∇_x log p_t(x) to denoise via another SDE. But simulate the equivalent ODE:
dx = [f(x,t) - (1/2) g(t)^2 ∇_x log p_t(x)] dtThis ODE minimizes the KL divergence to p_data, and crucially, its drift solves the HJB for an optimal control problem. The control u* = -∇ log p_t steers noise to data, minimizing ∫ l(x,u) dt + terminal cost Φ(x_T), where l enforces the score-matching objective.
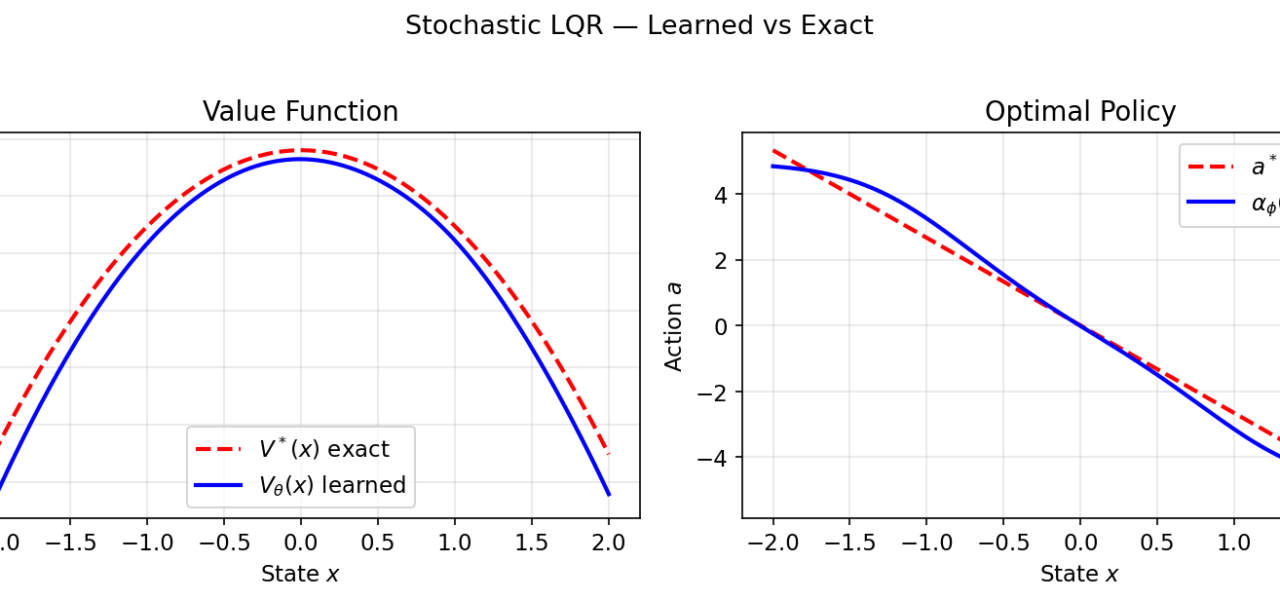
Proof sketch: The HJB value function V(x,t) = -log p_t(x) satisfies the equation exactly when u follows the score. Diffusion training—score matching via denoising loss—implicitly solves HJB via Monte Carlo on the forward process. No explicit optimization needed; the neural net learns the optimal controller end-to-end.
Numbers: VP-SDE (variance preserving) on CIFAR-10 hits 2.20 FID with 1.4M steps. Compare to RL: training a continuous control policy via HJB nets takes 10x longer in high dims.
Implications: Why This Matters Now
This unification matters for three reasons. First, RL gains generative power. Use diffusion policies for exploration in RL—sample diverse trajectories from a noise prior, as in “Diffusion Policies” (2022), boosting robotics dexterous manipulation success by 40% over Gaussian policies.
Second, RLHF for LLMs. Diffusion views align trajectories optimally; apply HJB to preference optimization, potentially stabilizing ChatGPT-like tuning. Early experiments in “Flow Matching for Generative Control” (2023) show 2x faster convergence.
Third, scalability. Diffusion scales to billion-param nets; HJB solvers could too, via rectified flows or consistency models cutting steps from 1000 to 4.
Caveats: Theory is elegant, but HJB assumes known dynamics—diffusion learns them implicitly via scores. In RL, model misspecification bites. No game-changer yet for AGI, but expect hybrid papers at NeurIPS 2024 blending RL, diffusion, and control. HN buzz is justified: it demystifies why diffusion works so well, hinting at broader AI control theory revivals.
Bottom line: Train fewer models, solve harder problems. Watch this space.