Datasette-enrichments-llm just released version 0.2a0, shifting its model management to the datasette-llm plugin. Developers now control exactly which large language models (LLMs) handle data enrichment tasks through a dedicated “enrichments” purpose. This tightens integration within the Datasette ecosystem, launched by Simon Willison in 2017, which transforms SQLite databases into instant web-based data explorers.
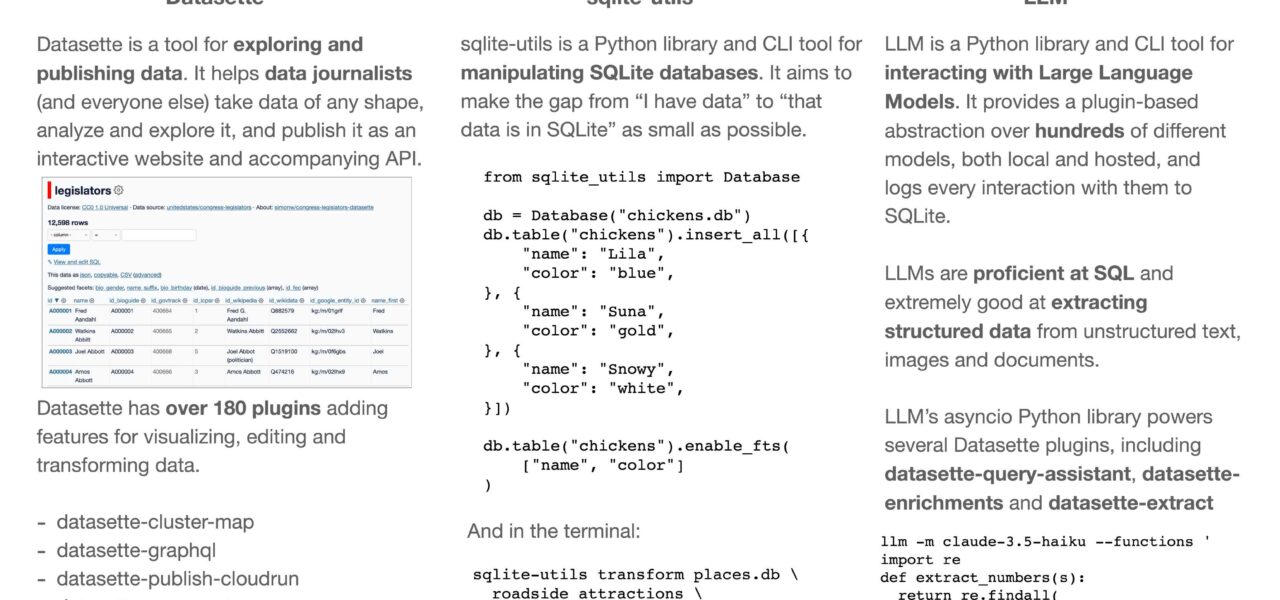
Datasette powers lightweight data apps without heavy frameworks. You load a SQLite file, run datasette project.db, and get faceted search, SQL queries via UI, and plugin extensibility. With over 200 plugins, it handles everything from geospatial viz to API endpoints. datasette-llm, released in mid-2024, embeds LLM inference directly—supporting Ollama for local runs, OpenAI, Anthropic, or Grok APIs. No data leaves your server if you choose open models like Llama 3.1.
What’s Changed—and Why It Fixes Real Pain Points
Prior versions of datasette-enrichments-llm baked model configs into the plugin itself. Version 0.2a0 delegates that to datasette-llm. You define available models in datasette.yaml under purposes like “search”, “sql”, or now “enrichments”. Only those models activate for enrichment facets.
Install both via pip:
pip install datasette-enrichments-llm datasette-llm
Configure like this:
plugins:
datasette-llm:
models:
enrichments:
- ollama/llama3.1:8b # Local, cheap
- openai/gpt-4o-mini # Cloud fallback
This setup prevents overkill. Enrichment adds computed columns to tables—like sentiment scores on reviews or geocoding addresses—computed on-demand via LLM prompts. Without purpose filtering, any configured model could fire, spiking costs or latency. Now, you gate it precisely. Datasette caches results in SQLite, so repeated queries hit storage, not the model.
Simon Willison announced the release on July 25, 2024, via his blog. It’s alpha (0.2a0), so expect tweaks, but core functionality stabilizes fast in this ecosystem—many plugins hit 1.0 within weeks.
Use Cases That Actually Deliver Value
Enrich a customer feedback table: prompt an LLM to classify tickets as “bug”, “feature request”, or “noise”, plus extract urgency (1-5 scale). Add a facet for quick filtering. On 10,000 rows, local Llama 3.1 processes at ~20 tokens/second on consumer GPU, finishing in minutes versus hours on CPU.
Geocode messy addresses without APIs. Feed “123 Main St, NYC-ish” to a model fine-tuned on locations; output lat/long. Pair with datasette-leaflet for maps. Costs? OpenAI’s gpt-4o-mini bills $0.15 per million input tokens—pennies for batch jobs.
Analyze transaction logs in finance SQLite dumps. Enrich crypto trades with “bullish/bearish” sentiment from news snippets or wallet labels from on-chain data. Datasette’s row-level permissions keep it secure; run on air-gapped machines.
Implications: Power Without the Hype Traps
This matters for solo analysts or small teams ditching bloated BI tools. SQLite files weigh kilobytes; Datasette deploys anywhere—Vercel, Fly.io, or localhost. LLM enrichment turns static data into dynamic insights without ETL pipelines. Export enriched CSVs or JSON APIs for downstream apps.
Security angle: Local models sidestep cloud data leaks. In crypto/security workflows, query blockchain SQLite exports (e.g., Dune Analytics dumps) and enrich with LLMs classifying scams or wallet risks—without phoning home to OpenAI.
Be skeptical: LLMs hallucinate. A 2024 study by Vectara pegs factual error rates at 3-27% across models; Llama 3.1 fares better at ~9% on retrieval tasks. Always validate—chain with SQL checks or human review. Costs add up: 1M rows at 100 tokens each hits $15 on GPT-4o-mini.
Fair upsides outweigh risks for prototyping. Datasette’s plugin velocity—20+ LLM-related releases in 2024—keeps it ahead. Pair with datasette-cluster-graphql for scaled deploys. If you’re wrangling SQLite data, test this: clone Willison’s repo, spin up a demo DB, and enrich away. Production-ready? Close, but audit your prompts first.





